- Deutsch
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Xilinx FPGA-Programmierung und Vivado-Designfluss erklärt
Katalog

Erforschen von Xilinx FPGA-Tutorials
Mit FPGAs zu arbeiten, kann sich zunächst geistig schwerer anfühlen als mit Software, partly because the goal isn’t to execute instructions but to describe hardware structures that run at the same time. Sie denken über Nebenläufigkeit, Taktregeln, Reset-Verhalten und ob Timing-Berichte mit dem übereinstimmen, was Sie gebaut haben. Wenn Menschen früh frustriert sind, liegt es oft nicht daran, dass ihnen der Einsatz fehlt, sondern daran, dass sich zu viele bewegliche Teile zwischen den Versuchen ändern, und die Ursache für das Versagen wird ärgerlich glatt.
Ein stetiger Weg nach vorne ist, denselben Arbeitsablauf zu wiederholen, bis er vertraut genug wird, dass Fehler auffallen. Halten Sie ein gut unterstütztes Xilinx-Board auf Ihrem Schreibtisch, beginnen Sie mit einem kleinen HDL-Design, simulieren Sie es, bis die Wellenformen sinnvoll sind, führen Sie Synthese und Implementierung in Vivado aus, programmieren Sie das Gerät und bestätigen Sie dann das Verhalten an echten Pins. Obwohl dieser Prozess repetitiv erscheinen mag, hilft er, die Unsicherheit zu verringern, ob ein Problem durch den Design-Code, die Beschränkungen oder die Board-Konfiguration verursacht wird, wodurch das Debugging effizienter wird.
Im Alltag des Lernens konzentriert sich der steile Teil der Kurve normalerweise auf einige Fähigkeiten, die sich gegenseitig verstärken: die Nutzung des Vivado-Flusses mit Disziplin, das Schreiben von synthesizable Verilog, das auf die Art und Weise abbildet, die Sie erwarten, und das Debuggen der unvermeidlichen Lücken zwischen Simulation und dem physischen Board mit einer Methode, der Sie vertrauen. Wenn Sie jeden Build als kontrolliertes Experiment behandeln, ändern Sie eine Variable, beobachten Sie den Effekt und notieren Sie, was Sie gesehen haben, werden Sie feststellen, dass Sie weniger Zeit mit Raten und mehr Zeit mit der Ausbildung zuverlässiger Instinkte verbringen.
Verwenden Sie den Projektfluss von Vivado auf eine Weise, die über die Zeit stabil bleibt
Vivado verhält sich weniger wie ein einfacher Kompilieren-Button und mehr wie eine Pipeline, die RTL in ein platziertes und geroutetes Design umwandelt, das innerhalb der elektrischen und zeitlichen Realitäten des Boards leben muss. Viele Anfänger entdecken, manchmal auf die harte Tour, dass viel Richtigkeit außerhalb des HDL liegt: Beschränkungen, Taktdefinitionen, I/O-Standards und Werkzeug Einstellungen können still entscheiden, ob die Hardware sich so verhält, wie die Simulation versprochen hat.
Ein sauberer Fluss beginnt damit, dass die Projektkonfiguration bescheiden und wiederholbar bleibt, damit Sie erkennen können, wann Sie das Design wirklich verbessert haben, im Gegensatz dazu, wenn Sie versehentlich die Umgebung geändert haben.
Wählen Sie ein unterstütztes Board und bleiben Sie lange genug dabei, um Intuition aufzubauen, die Sie wiederverwenden können. Boards mit solider Dokumentation und Referenzdesigns neigen dazu, die Hintergrundangst zu verringern, da Sie Ihre Pinbelegung, Takt und Stromannahmen überprüfen können, ohne nach inoffiziellen Forenbeiträgen suchen zu müssen.
Beginnen Sie mit einem Top-Modul, das schnell ein sichtbares Ergebnis erzeugt. Dieses sofortige Feedback hilft Ihnen zu bestätigen, dass der Takt läuft, Pins korrekt zugeordnet sind und Bitstreams auf die Weise generiert werden, die Sie denken, dass sie es sind.
Beispiele für beobachtbares Verhalten auf der obersten Ebene:
• Eine blinkende LED
• Ein UART-Echo
• Ein Zähler, der GPIO steuert
Eine praktische Gewohnheit besteht darin, ein kleines, standardisiertes Über-Template frühzeitig festzulegen. Zum Beispiel, halte einen Uhreneingang, einen Rücksetzansatz, den du verstehst, und ein kleines, konsistentes GPIO-Bündel. Wenn das Gerüst von Projekt zu Projekt gleich bleibt, kannst du deine Aufmerksamkeit auf die neue Logik richten, anstatt die Grundlagen jedes Mal neu abzuleiten, was sich mühsam und überraschend fehleranfällig anfühlen kann.
Einschränkungen sind ein zentraler Bestandteil des FPGA-Designs und nicht nur ein abschließender Anpassungsschritt. Viele frühe Hardwareprobleme treten auf, selbst wenn das RTL-Design korrekt ist, weil Uhr-Einschränkungen fehlen oder fehlerhaft sind, Pins falsch zugewiesen sind oder I/O-Standards nicht mit den tatsächlichen Anforderungen des Boards übereinstimmen.
Ein konkreter Workflow, der dich ehrlich hält, besteht darin, Uhren in XDC zu definieren, Ports unter Verwendung des Master-XDC des Anbieters als Referenz zuzuordnen und dann die I/O-Standards mit dem Schaltplan des Boards zu überprüfen. Dieser Prozess kann sich anfangs etwas bürokratisch anfühlen, aber er neigt dazu, vage Verdachtsmomente durch überprüfbare Fakten zu ersetzen.
Timing-Abschluss ist auch nicht nur für schnelle Designs reserviert. Selbst Logik, die auf dem Papier langsam aussieht, kann sich schlecht verhalten, wenn das Werkzeug unbeabsichtigte Uhrbeziehungen ableitet oder wenn asynchrone Signale nachlässig behandelt werden. Sich frühzeitig mit dem Lesen von Timing-Berichten wohlzufühlen, kann das unangenehme Gefühl von „Ich hoffe, das ist in Ordnung“ verringern, wenn die Designs größer werden.
Vivado sagt dir ständig, was es von deinem Design hält; der schmerzhafte Teil ist, dass es einfach ist, über die Warnungen hinwegzuklicken und dann Stunden mit der Fehlersuche eines Problems zu verbringen, das bereits auf der Konsole beschrieben wurde. Im Laufe der Zeit sind die Menschen, die schneller vorankommen, oft diejenigen, die sich eine ruhige Gewohnheit angeeignet haben, Berichte nach jedem Lauf zu überprüfen, selbst wenn sie erwarten, dass alles in Ordnung ist.
Nach jedem Synthese-/Implementierungslauf halte diese Berichts Kategorien zusammen auf deiner eigenen Checkliste:
• Timing-Status und kritische Pfade
• Ressourcennutzung (LUT/FF/BRAM/DSP) im Vergleich zu Erwartungen
• Inferenz Ergebnisse (für RAMs, DSP-Blöcke und andere beabsichtigte Strukturen)
Wenn eine Warnung seit dem ersten Build vorhanden ist, taucht sie oft in den seltsamsten Fehlern später wieder auf. Eine produktive Haltung besteht darin, anzunehmen, dass Warnungen Aufmerksamkeit verdienen, bis du erklären kannst, in einfachen ingenieurtechnischen Begriffen, warum sie für dein spezifisches Design harmlos sind.
Schreibe synthetisierbares Verilog, das sauber auf FPGA-Hardware abbildet
HDL-Arbeit ist näher am Schaltungsdesign als an der Anwendungsentwicklung, und dieser Wechsel kann emotional erschütternd sein: Du kannst gültiges Verilog schreiben, das wunderschön simuliert, aber in etwas Langsameren, Größeren oder einfach anderem synthetisiert, als du dir vorgestellt hast. Das Ziel ist es, Strukturen zu beschreiben, die das FPGA vorhersehbar implementieren kann: Flip-Flops, LUT-Logik, BRAM und DSP-Blöcke, damit Verhalten und Timing mit deiner Absicht übereinstimmen.
Wenn das Mapping vorhersehbar ist, fühlt sich das Debuggen weniger wie ein Streiten mit dem Werkzeug und mehr wie das Verfeinern eines Designs an.
Eine bequeme Grundlage für viele Anfänger ist ein einzelner Taktbereich mit unkomplizierter synchroner Logik. Verwende taktbetriebene Always-Blöcke für sequenzielle Zustände und kontinuierliche Zuweisungen (oder richtig geschriebene kombinatorische Blöcke) für kombinatorische Wege. Die Erstellung von „uhrähnlicher“ Logik im Fabric kann in Nischenfällen funktionieren, aber sie neigt dazu, Risiken in Bezug auf Taktbereiche einzuladen, es sei denn, du verstehst bereits Taktgating, Routing und Timing-Auswirkungen.
Das Rücksetzverhalten ist ein weiterer Bereich, in dem kleine Entscheidungen überraschend inkonsistente Ergebnisse auf dem Board erzeugen können. Asynchrone Rücksetzungen können nützlich sein, aber sie können auch Deaktivierungsgefahren oder Empfindlichkeit gegenüber boardbezogenen Unterschiede bei der Stromversorgung verursachen. Viele FPGA-Designs verwenden vollständig synchrone Rücksetzungen oder asynchrone Aktivierungen mit synchroner Freigabe, da diese Ansätze helfen, inkonsistentes Startverhalten während der Inbetriebnahmetests zu reduzieren.
FPGA-Logik neigt natürlich zu Pipelines und parallelen Strukturen. Eine häufige Enttäuschung bei Anfängern besteht darin, ein softwareähnliches Schritt-für-Schritt-Ablauf zu erwarten und dann verwirrt zu sein, wenn alles gleichzeitig passiert. Eine nützlichere Perspektive ist, zu entscheiden, was dir für einen bestimmten Block wichtig ist, und dann explizit für dieses Ergebnis zu entwerfen.
Eine Einzeilige Design-Perspektive für Leistung und Mapping:
• Durchsatz (Einheiten pro Takt)
• Latenz (Zyklen von Eingabe zu Ausgabe)
• Ressourcenzuordnungspräferenz (LUTs vs BRAM vs DSP)
Zum Beispiel kann ein Multiplizieren-Akkumulieren DSP-Slices sauber ableiten, aber kleinere Änderungen im Programmierstil können das Werkzeug in Richtung LUT-basierter Arithmetik bewegen. Wenn die Nutzung dich überrascht, ist es oft wert, innezuhalten und eine etwas unangenehme Frage zu stellen: Hast du tatsächlich die Hardware-Struktur beschrieben, die du beabsichtigt hast, oder hast du etwas funktional Gleichwertiges beschrieben, das mehr Ressourcen kostet?
Simulation wird gerne Konstrukte akzeptieren, die echte Hardware nicht so umsetzen kann, wie du dir vielleicht vorstellst. Das Halten Deiner synthetisierbaren Grenze klar reduziert falsches Vertrauen und macht Simulationsergebnisse tragbarer für das Board.
Häufige Muster, die als schnelle Erinnerung auf einer Zeile gruppiert werden sollten:
• Verzögerungen (#) in synthetisierbarer Logik vermeiden
• Verlassen Sie sich nicht auf die Initialisierung, es sei denn, Sie haben das Verhalten des Geräts/Werkzeugs bestätigt
• Achten Sie auf unbeabsichtigte Latches aus unvollständigen kombinatorischen Zuordnungen
• Verwenden Sie geeignete Synchronisierer für die Überquerung von Takt-Domänen
Eine Gewohnheit, die sich auszahlt, ist das Schreiben kleiner selbstüberprüfender Testbenches, die die Annahmen validieren, zu denen man emotional geneigt ist, sie einfach zu ignorieren: Rücksetzverhalten, Zählerüberlauf, Handshake-Protokolle und Grenzbedingungen. Wenn Projekte wachsen, werden diese Tests weniger wie Zusatzarbeit und mehr wie das, was Sie davon abhält, alles in Frage zu stellen.
Systematisch mit Simulation und On-Chip-Sichtbarkeit (ILA) debuggen
Selbst ausgezeichnete Simulation verspricht nicht das korrekte Verhalten des Boards. Echte Hardware bringt Takt-Jitter, I/O-Verzögerungen, unbekannte Anfangszustände und asynchrone Eingänge, die sich nicht brav mit Ihrer Taktflanke ausrichten. Die schnellsten Debugger sind normalerweise nicht die, die zufällige Änderungen vornehmen; sie sind diejenigen, die das Problem mit strukturierter Beobachtung eingrenzen und erklären können, welche Beweise ihre Meinung geändert haben.
Eine starke Testbench überprüft das Verhalten über viele Zyklen und meidet unangenehme Szenarien nicht. Wenn Sie realistische Stimuli modellieren, wird die Simulation zu einem Ort, an dem Sie Vertrauen aufbauen, nicht nur zu einem Ort, an dem Sie beobachten, wie ein Signal umschaltet und hoffen, dass es etwas bedeutet.
Realistische Stimuli, die dazu neigen, fragilen Logik aufzudecken:
• Tastendämpfung
• UART-Rahmungsfehler
• Rückdruck in Streaming-Schnittstellen
• Rücksetzsequenzen mit unangenehmer Timing
Es hilft auch, Fehler in zwei Kategorien zu trennen, damit Sie nicht die falsche Art von Lösung suchen:
• Funktionale Fehler: Die Logik des RTL ist falsch
• Integrationsfehler: Der RTL ist in Ordnung, aber Takt/Rücksetzungen/Restriktionen/I/O-Annahmen sind falsch
Die Simulation ist hervorragend darin, funktionale Fehler herauszufiltern; Board-Tests zeigen oft Integrationsfehler, von denen Sie nicht glauben wollten, dass sie möglich sind.
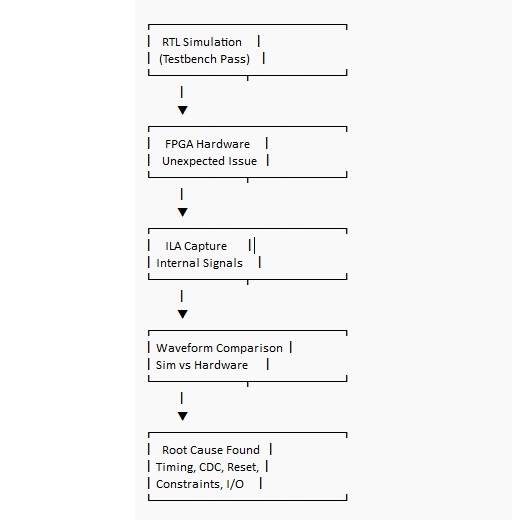
Wenn sich das Hardwareverhalten nicht mit Ihrer Testbench deckt, ist der Integrierte Logikanalysator (ILA) oft der direkteste Weg, Spekulationen durch einen Trace zu ersetzen, den Sie untersuchen können. Untersuchen Sie Signale, die Entscheidungen und Grenzen im Design darstellen, erfassen Sie dann den Moment, in dem sich die Dinge unterscheiden, und vergleichen Sie ihn mit der erwarteten Simulationswelle.
Signale, die tendenziell wertvolle Proben sind:
• FSM-Zustandskodierungen
• gültige/bereite Handshakes
• FIFO voll/leerer Flags
• Ausgaben des Rücksetzsynchronisierers
Ein praktischer Workflow besteht darin, mit weniger Proben und einem breiteren Erfassungsfenster zu beginnen. Während Sie lernen, wo der Fehler liegt, können Sie den Auslöser verengen und Details hinzufügen. Übermäßiges Instrumentieren kann die Timing-Marge verringern und den Bau komplizieren, daher ist es oft gesünder, die ILA-Integration als einen fokussierten Messschritt zu betrachten, als etwas, das man nur für den Fall beibehält.
Einige der lehrreichsten Fehler passieren, wenn die Simulation makellos aussieht und das Board instabil ist. Dieser Unterschied kann entmutigend sein, aber es ist auch der Punkt, an dem die FPGA-Intuition schärfer wird, denn die Lösung liegt normalerweise im Takt, in den Einschränkungen oder in der Signalhygiene und nicht im Algorithmus.
Häufige Ursachen für Divergenzen zwischen Simulation und Board:
• Fehlende oder falsche Taktbeschränkungen
• Metastabilität durch unsynchrone Eingänge
• Variationen der Rücksatzfreigabezeiten über den Chip
• CDC-Probleme zwischen mehreren Takt-Domänen
• Unterschiede in den Anfangsbedingungen
Eine Perspektive, die das Lernen beschleunigt, besteht darin, Timing und Beobachtbarkeit als Eigenschaften zu betrachten, die Sie absichtlich in das Design einbauen. Wenn Ihre kleinen Projekte Taktfrequenzen explizit definieren, I/O einschränken, Überquerungen synchronisieren und interne Signale zur Messung offenlegen, verbringen Sie weniger Zeit mit der Hoffnung, dass es funktioniert, und mehr Zeit damit, kontrollierte, erklärbare Verbesserungen vorzunehmen. Diese Denkweise skaliert natürlicherweise von einer blinkenden LED zu größeren Pipelines, Schnittstellen und eingebetteten Systemen auf demselben Gerät.
Xilinx (AMD) vs. Altera (Intel) FPG
Xilinx (AMD) und Intel (Altera) liefern beide FPGA-Familien, die auf dem Papier vergleichbar aussehen, und es ist einfach, sich nach einem schnellen Blick in das Datenblatt sicher zu fühlen. Die Stimmung ändert sich tendenziell später, wenn die alltäglichen Engineering-Realitäten das Tempo bestimmen: das Verhalten der Werkzeuge auf Ihrem genauen Gerät und Geschwindigkeitsgrad, ob die IP, von der Sie annahmen, dass Sie sie verwenden können, tatsächlich in Ihrer Organisation lizenziert ist, ob ein Referenzdesign wirklich mit Ihren Taktfrequenzen und Rücksetzungen übereinstimmt und ob der Timing-Abschluss stabil bleibt, sobald das Design produktionsreif wird.
Ein Auswahlprozess hält sich besser, wenn Sie das FPGA als ein Liefersystem betrachten, Gerät + Werkzeuge + IP + Boards + Dokumentation + langfristige Wartbarkeit, denn dort gewinnen die Teams entweder an Schwung (und Schlaf) oder sammeln stillen Zeitplanstress an.
| Funktion |
Xilinx (AMD) |
Intel (Altera) |
| Marktposition |
Historisch der Marktführer, bekannt für ein breites Produktportfolio und als Pionier bei neuen Technologien. |
Starker Konkurrent, insbesondere leistungsfähig in Rechenzentrums- und Netzwerk-Anwendungen, nutzt Intels Fertigungskompetenz. |
| Kernarchitektur |
Die Logik basiert hauptsächlich auf 6-Eingangs-Look-Up-Tabellen (LUTs), die hohe Granularität und Flexibilität bieten. |
Verwendet Adaptive Logic Modules (ALMs), die komplexer sind und als größere LUTs konfiguriert werden können, was die Logikdichte für bestimmte Designs potenziell verbessert. |
| Software-Suite |
Vivado Design Suite und Vitis Unified Software Platform. Oft für ihre benutzerfreundliche Oberfläche für erfahrene Entwickler gelobt. |
Quartus Prime Design Suite. Einige Benutzer finden seine GUI für Anfänger intuitiver, und sie ist für schnellere Kompilierzeiten in einigen Szenarien bekannt. |
| Hochleistungsfamilien |
Versal ACAPs (Adaptive Compute Acceleration Platforms), die skalare, anpassbare und intelligente Engines kombinieren. |
Agilex FPGAs, bekannt für hohe Leistung und Energieeffizienz, wobei einige Benchmarks einen Vorteil in der Leistung pro Watt zeigen. |
| Ökosystemfokus |
Starker Fokus auf die Integration von Prozessor und FPGA, wie in der Zynq-Familie zu sehen. Beliebt für die Anwendungsentwicklung. |
Gut geeignet für System-on-Chip-Designs und industrielle Anwendungen, mit einem starken IP-Portfolio für Netzwerke und RF. |
Auswahl durch verifizierbare Constraints definieren, nicht durch Markterwartungen
Beginnen Sie mit Anforderungen, die Sie frühzeitig testen können, nicht mit Eindrücken aus früheren Projekten. Das Ziel ist es, "Überraschungen in Woche 10" zu reduzieren, wo Frustration und Nacharbeit häufig anfallen.
Checkliste für Constraints:
• Logikressourcen: LUTs/ALMs, Register, Verfügbarkeit der Routingressourcen und erwartete Auslastungsgrenze
• DSP-Ressourcen: Blockanzahl, Präzisionsmodi, Voraddierer, Kaskade/topologische Optionen und Zuordnungsverhalten für Ihre Mathematikkerne
• On-Chip-Speicher: BRAM/URAM (oder M20K-Äquivalente), Gesamtkapazität, Portmodi, Bandbreite pro Takt und Inhaltungsmuster
• Hochgeschwindigkeits-I/O: SERDES-Klasse, Anzahl der Kanäle, maximale Datenrate, Referenzuhroptionen und Protokollunterstützung, die an Ihren Anwendungsfall gebunden ist
• Externer Speicher: DDR3/DDR4/LPDDR-Varianten, Reife des Controllers, Kalibrierungsverhalten und Annahmen zu SI-Margen auf Board-Ebene
• Latenz und Determinismus: End-to-End-Ziel, Budget pro Stufe, Jittertoleranz und CDC-Strategie (einschließlich wie Resets Domänen überqueren)
• Leistungs-/Wärmerahmen: Worst-Case-Schaltabschätzungen, Transceiver-Energiebetriebsmodi, Kühlannahmen und Umgebungsbereich
Echte FPGA-Projekte zeigen oft, dass es nicht garantiert, dass die Eignung innerhalb des Geräts zuverlässigen Hochgeschwindigkeitsbetrieb gewährleistet. Designs, die bei 70–80% Auslastung akzeptabel erscheinen, können nach dem Hinzufügen von Debug-Logik, CDC-Schutz, FIFOs, Fehlerbehandlung und Timing-Margen, die für den praktischen Betrieb erforderlich sind, instabil werden.
Wenn Ihr Team jemals eine Woche durch Routing-Stau verloren hat, ist der Reiz, auf eine größere Gerätegröße zu wechseln, leicht nachvollziehbar. Der Kostenhandel ist in der Regel nicht linear: Ein leicht größeres Bauteil kann ruhigere Timings, weniger Werkzeuggenerationen und weniger nächtliche Neuaufbauten kaufen.
Behandeln Sie den Tool-Flow wie ein Erfordernis, das Sie nicht wegwünschen können
Der Tool-Flow ist oft der unsichtbare Unterschied zwischen einem soliden Plan und einem Plan, der ständig rutscht. Menschen unterschätzen oft, wie viel emotionale Bandbreite bei langsamen oder unvorhersehbaren Iterationen verbrannt wird, insbesondere wenn ein Build Stunden dauert und der Fehlerzustand vage ist.
Checkliste zur Tool-Flow-Bewertung:
• Iterationsgeschwindigkeit: Synthese + Platzierung/Routing + Bitstream-Zeit auf Ihrer CI-Hardware, nicht auf einer Demomaschine des Anbieters
• Timing-Abschlussverhalten: QoR-Trends, Stabilität über Seeds hinweg und Empfindlichkeit gegenüber kleinen Änderungen der Constraints
• Constraints und Beobachtbarkeit: SDC/XDC-Klarheit, Genauigkeit der Taktmodellierung, Behandlung von falschen Pfaden/mehrteiligen Zyklen und wie debuggierbar Verstöße sind
• Debug-Instrumentierung: Einfügefluss für Logikanalysatoren, Flexibilität der Sonden, Trigger-Tiefe und wie oft Sie neu kompilieren müssen, um Signale zu beobachten
• Umgebungsanpassung: unterstützte OS-Versionen, headless Builds, Lizenzprobleme und wie gut es zum Arbeitsablauf Ihres Teams passt
• CI/VCS-Freundlichkeit: Reproduzierbarkeit, deterministische Ausgaben (so viel es die Werkzeuge zulassen), Skriptfähigkeit und Upgrade-Schmerzen
Bevor Sie sich festlegen, führen Sie einen Timing-Abschlussversuch bei etwas Repräsentativem durch (nicht bei einem Spielzeug). Schließen Sie Ihre echten Uhren ein, mindestens eine externe Speicher Schnittstelle und mindestens einen Hochgeschwindigkeits-I/O-Bereich ein. Verfolgen Sie:
• Wand-Uhr-Kompilierungszeit pro Iteration
• Stabilität des Slack über einige Seeds
• Wie schnell ein Ingenieur die ersten drei Timing-Probleme ohne Stammeswissen diagnostizieren kann
Dieses Experiment tendiert dazu, eine Art Klarheit zu erzeugen, die Checklisten für Funktionen nicht bieten. Es zeigt auch, ob Ihr Team sich während der Integrationsphase stabil oder ständig angespannt fühlen wird.
IP Verfügbarkeit und Lizenzierung: Wo Zeitpläne oft eng werden
Selbst wenn rohe FPGA-Ressourcen ähnlich aussehen, hängen Zeitpläne oft von IP-Re realitäten ab. Hier können Teams sich überrumpelt fühlen: der Kern existiert, aber das Lizenzmodell, der Integrationsaufwand oder die Dokumentationsqualität verwandeln es in einen langwierigen Prozess.
IP- und Lizenzcheckliste:
• Protokollstapel: PCIe, Ethernet MAC/PCS, JESD204, DDR-Controller und alle Nischen-Schnittstellen, die Sie nutzen
• Lizenzbedingungen: node-locked vs. floating, Funktionserweiterungen, Build-Server/CI-Auswirkungen und alle Laufzeit- oder Bereitstellungseinschränkungen
• Referenzdesigns: Lane-Zahlen, Taktplan, Reset-Sequenzierung, DMA-Architektur und ob es zu Ihren Systemgrenzen passt
• Unterstützungszeitraum: Erwartungen an die langfristige Wartung, Patch-Frequenz und wie Probleme priorisiert werden
Ein subtiler Punkt, den Teams auf die harte Tour lernen: Verfügbare IP ist nicht dasselbe wie Plug-and-Play-IP. Labordemos können die Integrationsarbeit verbergen, die nötig ist, um Ihre Latency-, Pufferspeicher- und Taktziele zu erreichen. Zeit für die Validierung einzuplanen und IP mit direkter Dokumentation und bekannten guten Beispielen zu bevorzugen, reduziert oft später das Stressniveau, auch wenn die anfängliche Bewertung langsamer erscheint.
Board-Ökosystem, Bring-Up-Risiko und der Komfort bekannter Plattformen
Die Wahl des FPGAs ist an die Board-Realität gebunden. Während des Bring-Ups verschwindet die Zeit oft in der Unsicherheit der Plattform anstatt im RTL: eine verpasste Takt-Bedingung, eine Reset-Abhängigkeit, die nicht offensichtlich war, oder ein Transceiver-Kanal, der nur bei bestimmten Temperaturen marginal ist.
Board- und Plattformcheckliste
• Evaluierungsboards und Referenzplattformen: Verfügbarkeit, Stabilität der Revision und ob das Design weit verbreitet ist
• Stromversorgungsleitlinien: PDN-Ziele, Entkopplungsansatz, Erwartungen an die Rail-Sequenzierung und Toleranzstapelanahmen
• Hochgeschwindigkeits-Layout-Referenzen: Richtlinien zur Transceiver-Routing, Compliance-Hinweise und bewährte Stapelungen
• Debug-Zugriff: JTAG-Stabilität, Boot/config-Modi, Unterstützung für Konfigurations-Flash und Sichtbarkeit in Rails/Takten
• Support-Reaktionsfähigkeit: Verkäuferkanäle, Signal-Rausch-Verhältnis der Community und Durchlaufzeit bei Tool/IP-Problemen
Die Verwendung einer weit verbreiteten Plattform mit bewährten Referenzdesigns kann das System-Bearbeitungs mehr strukturiert und vorhersehbar machen. Dieser Ansatz hilft, die Fehlersuche von allgemeiner Unsicherheit zu schrittweiser messbarer Verifikation zu bewegen, was die Entwicklungseffizienz verbessert.
Timing-Abschluss
Timing-Abschluss ist der Punkt, an dem Unterschiede zwischen Anbietern greifbar werden, insbesondere wenn die Auslastung steigt und mehrere Taktbereiche interagieren. In diesem Stadium kann der Fortschritt des Designs entweder stabil und vorhersehbar bleiben oder schwierig werden, wenn kleine Änderungen große Timing-Variationen erzeugen.
• Überlastungsskala: wie der Routing-Druck zunimmt, während die Auslastung steigt, und wo er zu steigen beginnt
• Fmax-Vorhersagbarkeit: wie oft moderate Einschränkungen Sie nahebringen, im Gegensatz zu starken manuellen Anpassungen
• Berichtqualität: ob Timing-Berichte auf anpassbare Lösungen hinweisen und nicht nur auf lange Verletzungslisten
• Robustheit: Verhalten über PVT-Variationen und unterschiedliche Implementierungssamen
Es ist im Allgemeinen sicherer anzunehmen, dass der Aufwand für den Abschluss nichtlinear mit der Dichte wächst. Über einen bestimmten Schwellenwert hinaus kann eine geringfügige RTL-Anpassung Slack von gesund zu fragil umschalten. Architektonisches Slack, Pipeline, selektives Floorplanning und die Wahl eines Geräts mit Raum zum Atmen schlagen oft heldenhafte Einschränkungstuning, das niemand gerne pflegt.
Vergleichen Sie das genaue Bauteil
Die Spezifikationen ändern sich über Generationen und innerhalb einer einzigen Familie. Zwei Teile mit ähnlichen Namen können sich stark genug unterscheiden, um einen Plan zu stören, insbesondere wenn Verpackung, Geschwindigkeitsgrad und Werkzeugreife ins Spiel kommen.
• Geschwindigkeitsgrad: erreichbares Fmax, Transceiver-Margenverhalten und Unterschiede im Timing-Modell
• Verpackung: I/O-Anzahl, Bankplatzierung, SI-Auswirkungen, thermisches Verhalten und Montagebedingungen
• SKU-Funktionseinschränkungen: deaktivierte Blöcke, reduzierte Transceiver-Fähigkeiten, Speicherverhältnisse oder Protokollbeschränkungen auf bestimmten Varianten
• Werkzeugreife: Gerätestützungsgrad, Veröffentlichungsfrequenz und ob Ihr Team auf einer stabilen Werkzeugversion standardisieren kann
Praktische Vergleichsmethode:
• Anbietertiming-Modelle, die auf Ihre tatsächlichen Taktungen und Schnittstellen abgebildet sind
• Leistungsabschätzung unter Verwendung realistischer Schaltfrequenzen, Duty-Cycles und Transceiver-Einstellungen
• Pinout/Bank-Einschränkungen, die an Ihre Board-Anforderungen und den Steckverbindungen ausgerichtet sind
• Werkzeugversionen, mit denen Ihre Organisation während der gesamten Produktlebensdauer leben kann (einschließlich CI)
Ein Entscheidungsrahmen, der sich oft bewährt, wenn die Dinge stressig werden
Wenn der Zeitdruck steigt, hilft ein Rahmen, der auf Messungen basiert, bedauernsgesteuerte Anpassungen zu vermeiden. Er trägt auch dazu bei, dass sich das Team wohler fühlt, da Entscheidungen eine papierbasierte Nachverfolgbarkeit zu beobachteten Ergebnissen besitzen und nicht zu Optimismus.
Ausgewogene Auswahlreihenfolge:
1) Messenbare Anforderungen festlegen: Ressourcen, I/O, Speicher, Latenz und Energie-/Wärmebudget.
2) Prototyp des schwierigsten Untersystems bei jedem Kandidaten erstellen: Timingverhalten + Debug-Workflow + Build/CI-Schleife.
3) IP-Reife und Lizenzen im Hinblick auf Ihren Integrationsplan bewerten, nicht auf Marketingzusammenfassungen.
4) Wählen Sie die Option mit Spielraum und der vorhersehbarsten Iterationsschleife, anstatt die, die gerade die Mindestanforderungen erfüllt.
Die Kernbotschaft ist, dass das beste FPGA selten das mit den auffälligsten Hauptzahlen ist. Teams bewegen sich normalerweise schneller und mit weniger Zweifeln, wenn die Plattform eine stetige Konvergenz, wiederholbare Builds und wartbare Lösungen über die Lebensdauer des Produkts unterstützt.
Die Kern-Toolchain

Vivados Rolle im FPGA-Workflow
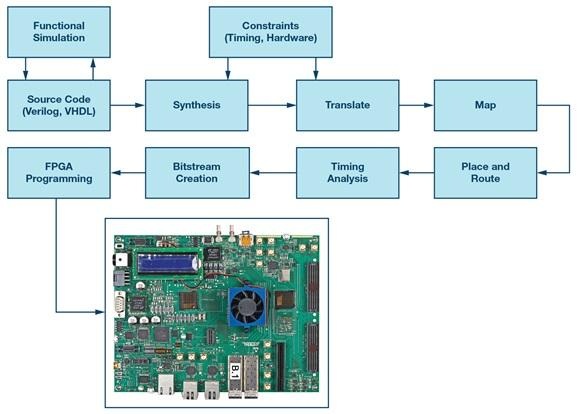
Vivado wird oft zum operativen Zentrum eines Xilinx FPGA-Projekts, nicht weil es glamourös ist, sondern weil es der Ort ist, an dem jede Annahme letztendlich gegen die Realität der Werkzeuge getestet wird. Es nimmt HDL und Einschränkungen auf, produziert eine Netzliste, führt Platzierung und Verlegung durch, während es Timing- und physikalische Entwurfsregeln ausbalanciert, und generiert dann einen Bitstream, der das Gerät programmiert.
Eine praktische Möglichkeit, Vivado zu verstehen, besteht darin, es als zwei verbundene Systeme zu betrachten: ein RTL-zu-Netzlistenkonversion-System und einen Optimierer für physikalische Implementierungen. Dies erklärt, warum logisch korrektes RTL dennoch instabile oder inkonsistente Ergebnisse liefern kann, wenn Einschränkungen unvollständig sind, Taktdimensionen ungenau sind oder die Entwurfsstruktur Routing- und Timingprobleme erzeugt.
Die meisten Projekte folgen einer vertrauten Pipeline, selbst wenn die Details nach Gerätefamilie und Flussstil variieren.
• Synthese: übersetzt RTL in eine Gatterebene und leitet gerätespezifische Strukturen ab.
• Implementierung: führt Platzierung, Verlegung und timinggesteuerte Optimierung unter physikalischen Einschränkungen durch.
• Bitstream-Generierung: gibt das Konfigurationsbild aus und überprüft das implementierte Ergebnis gegen Einschränkungen und Werkzeugregeln.
Ein Zeitplan wird oft dann angespannt, wenn ein Bitstream einmal produziert wird, aber wenn das Team benötigt, dass der Bitstream wie ein verlässliches Ergebnis funktioniert: ähnliche Ergebnisse bei Wiederherstellungen, Timingmargen, die bei der Zielgeschwindigkeitsgrad bestehen bleiben, und Stabilität, wenn kleine RTL-Änderungen für funktionale Korrekturen vorgenommen werden. Das ist der Punkt, an dem es nicht mehr beruhigend ist, dass es gestern funktioniert hat.
Teams, die schneller vorankommen, hören normalerweise auf, Berichte als Papierkram zu behandeln, und beginnen, sie als technische Beweise zu betrachten. Wenn die Build-Artefakte konsistent gesammelt werden, werden Entwurfsdiskussionen weniger emotional und konkreter, was eine Erleichterung ist, wenn Fristen nah sind.
• Synthese-/Implementierungsberichte: Nutzung, abgeleitete Primitiven, Warnungen und strukturelle Zusammenfassungen.
• Timing-Ausgaben: WNS/TNS, fehlgeschlagene Endpunkte, detaillierte Pfade und Zusammenfassungen der Takt-Interaktionen.
• XDC-Einschränkungen: Takt, I/O-Regeln, Ausnahmen und physikalische Pin-Zuweisungen.
• Implementierte Kontrollpunkte (DCP): reproduzierbare Snapshots, die schnelle Iteration und kontrollierte Experimente unterstützen.
Ein Muster, das sich in der realen Arbeit zeigt, ist, dass ein gepflegtes, intern konsistentes Berichtset oft reibungsloseren Fortschritt vorhersagt als ein einzelnes grünes „PASS“-Banner. Das Banner kann Zerbrechlichkeit verbergen; die Berichte tun dies normalerweise nicht.
Installation und Umgebungseinrichtung
Eine Einrichtung, die lediglich die GUI startet, ist einfach zu feiern und später leicht zu bedauern. Die Setups, denen die Teams vertrauen, sind auf eine gute Art langweilig: Sie verhalten sich unter Automatisierung gleich, sind konsistent über Maschinen hinweg und überraschen nicht nach einem Werkzeugupdate.
Wählen Sie die Vivado ML-Edition, die Ihren Zielgeräten entspricht, und aktivieren Sie dann nur die Gerätefamilien, die Sie tatsächlich planen zu bauen. Dies verringert den Speicherplatzbedarf und die Indizierungszeit und reduziert auch die Wahrscheinlichkeit von versehentlichen konfigurationsübergreifenden Fehlern, die einen Nachmittag kosten können.
In Entwicklungsteams mit mehreren Boards hilft das Führen einer definierten Liste von unterstützten Geräten für jedes Projekt, die Entwicklung kontrollierter und konsistenter zu halten, als sich auf die Werkzeuge oder Teile zu verlassen, die zufällig installiert sind.
Vivado-Ausgaben können sich zwischen Versionen ändern, weil sich Platzierungs-, Verlegungs- und Timingalgorithmen weiterentwickeln und Fehler behoben (oder durch andere Fehler ersetzt) werden. Viele Teams erhalten ruhigere Builds, indem sie eine Werkzeugversion pro Release-Branch festlegen und in geplanten Schritten upgraden, anstatt kontinuierlich zu driften.
Bei der Ausprobierung einer neueren Version vergleichen die Teams häufig die praktischen Signale der Tool-Gesundheit, bevor sie es als neue Basislinie übernehmen: Timing-Margen, Änderungen der Auslastung, Warn-Deltas und alle neuen Constraint-Coverage-Nachrichten. Die Zeit, die für diesen Vergleich aufgebracht wird, ist in der Regel einfacher, als spät im Zyklus darüber zu streiten, ob das Timing plötzlich ohne Grund schlechter geworden ist.
Für Builds über die Kommandozeile, CI-Systeme und gemeinsame Build-Server muss die Entwicklungsumgebung konsistent auf allen Systemen funktionieren, anstatt von einzelnen Maschinenkonfigurationen abhängig zu sein.
• Einstellungs-Skripte: die richtigen Tool-Einstellungen laden, damit Pfade, Bibliotheken und Laufzeitabhängigkeiten konsistent aufgelöst werden.
• Tcl-gesteuerte Abläufe: bevorzuge skriptbasierte Builds für wiederholbare Durchläufe, einheitliche Berichterstattung und CI-Integration.
• Disziplin der Build-Schnittstelle: halte Eingaben und Ausgaben stabil, damit Änderungen absichtlich und überprüfbar sind.
Ein gängiger Entwicklungs-Workflow besteht darin, zunächst einen stabilen GUI-Build abzuschließen, um das Design zu verifizieren, und dann zu einem Tcl-basierten Ablauf zu wechseln, damit der Build-Prozess nicht mehr von GUI-Einstellungen, zwischengespeicherten Daten oder Unterschieden zwischen Entwicklungsmaschinen abhängt.
Die Berichte, die Sie lesen möchten, wie Diagnosen
Die meisten gescheiterten Design-Momente sind nicht lange mysteriös, wenn die Berichte als Geschichte dessen gelesen werden, was das Tool geglaubt hat. Warnungen, Constraint-Coverage und Timing-Pfade neigen dazu, den Fehlerzustand offen zu dokumentieren, obwohl nicht immer in der freundlichsten Reihenfolge.
Teams verbessern sich am schnellsten, wenn sie die Ausgaben von Vivado als täglichen Feedback-Zyklus behandeln, anstatt etwas zu öffnen, das nur dann verwendet wird, wenn der Build fehlschlägt.
Diese Berichte sind oft der erste Ort, an dem eine Abweichung in der Absicht sichtbar wird, und das kann seltsamerweise beruhigend sein: Zumindest ist das Problem konkret.
• Ressourcenauslastung: LUT, FF, BRAM, DSP, URAM im Vergleich zu Gerätegrenzen und Spielraum.
• Inferenzprüfungen: unerwartete RAM-Stile, fehlende DSP-Inferenz, überraschende primitive Zuordnungen.
• Strukturelle rote Flaggen: hochverzweigte Netze, breite Multiplexer, lange kombinatorische Ketten.
• Warnungen: Latch-Inferenz, unvollständige Sensitivitätsbehandlung, nicht verbundene oder gekürzte Logik.
Latch-Inferenz und unbeabsichtigte lange kombinatorische Pfade treten in der Praxis häufig auf. Das Tool wird sie ohne Beschwerde implementieren, und das kann irreführend sein, wenn das Timing später auf eine Weise nicht kooperieren will, die zufällig erscheint, bis die Pfadberichte gelesen werden.
Timing-Abschluss wird weniger stressig, wenn das Team weiß, was das Tool optimiert und warum es bestimmte Kompromisse wählt.
• Slack-Signale: WNS als die schlimmste einzelne Verletzung; TNS als die allgemeine Verbreitung der Verletzungen.
• Pfadaufteilung: wo sich Verzögerungen ansammeln (Logik-Tiefe, Routing, Taktung oder Annahmen zu Einschränkungen).
• Taktmodellierung: ob Pfade wie beabsichtigt analysiert, ignoriert oder falsch gruppiert werden.
Eine nuancierte Lektion, die erfahrene Teams verinnerlichen, ist, dass Timing-Schmerzen oft zuerst ein Problem der Constraints-Modellierung und zweitens ein RTL-Problem sind. Wenn das Taktmodell falsch ist, kann es Tage damit verbringen, die falschen Endpunkte zu optimieren und sich dennoch anfühlen, als würde das Tool nicht zuhören.
Constraint-Lücken sind ein wiederholter Übeltäter, zum Teil weil sie nicht immer dramatisch erscheinen, bis das Projekt weit fortgeschritten ist.
• Lücken bei der Taktdefinitions: fehlende oder falsche Primärtakte.
• Lücken bei den generierten Takten: geteilte/multiplikative/weitergeleitete Takte, die nicht deklariert sind und das Tool zwingen, zu raten.
• Lücken bei der I/O-Definition: fehlende I/O-Constraints, die zu optimistischen Annahmen und späteren Überraschungen auf der Platine führen.
• Missbrauch von Ausnahmen: fehlende Ausnahmen oder Ausnahmen, die zu allgemein sind, um zuverlässig zu sein.
Eine pragmatische Gewohnheit besteht darin, die XDC als lebende Spezifikation und nicht als Patch-Datei zu behandeln. Wenn Ausnahmen eingeführt werden, neigen Teams, die besser schlafen, dazu, sie eng, erklärt und an eine reale Timing-Beziehung gebunden zu halten, anstatt sie zu verwenden, um Verletzungen zu beruhigen, die einer Überprüfung bedürfen.
XDC Constraints-Strategie
Die XDC-Datei ist der Ort, an dem die Designabsicht gezwungen wird, explizit zu werden. Wenn sie leicht falsch ist, kann sich das resultierende Timing-Verhalten chaotisch anfühlen, auch wenn das Tool perfekt deterministisch ist.
Definieren Sie Takte explizit und überprüfen Sie dann, ob das Tool sie so propagiert hat, wie Sie es erwartet haben. Taktmodell-Probleme sind oft einfacher zu korrigieren als tiefere architektonische Timing-Probleme, was sie während der Timing-Analyse und des Debuggings einfacher zu lösen macht.
• Primärtakte: definiert von Pins oder von MMCM/PLL-Ausgängen.
• Generierte Takte: definiert für geteilte, multiplizierte oder weitergeleitete Domänen.
• Asynchrone Beziehungen: deklariert über Taktgruppen oder explizite Beziehungen.
Auf echten Platinen kann ein verpasster generierter Takt ein irreführendes Timing-Bild erzeugen, das Tage in Anspruch nimmt, insbesondere wenn das Tool auf Endpunkte optimiert, die nie zusammen analysiert werden sollten.
I/O-Beschränkungen prägen die elektrischen und zeitlichen Annahmen, die das Tool verwendet, und können leise bestimmen, ob der Laborsuccess in "Systemerfolg" übergeht.
• Elektrische Standards: I/O-Standards und Spannungen, die mit dem Board-Design übereinstimmen.
• Pinning-Disziplin: Pin-Standorte sperren, sobald das Mapping stabil ist, um Wechselwirkungen zu vermeiden.
• Schnittstellentiming: Eingabe-/Ausgabeverzögerungen, die das externe Gerät widerspiegeln, nicht die Standardwerte des Tools.
Eine vertraute Enttäuschung in der späten Phase lautet: Es erfüllte die Timing-Vorgaben im Build, aber die Schnittstelle versagt unter echtem Verkehr. Dieses Ergebnis lässt sich oft auf Standardannahmen für I/O zurückführen, die nie aktualisiert wurden, um mit den Timing-Budgets des Boards und des externen Geräts übereinzustimmen.
Ausnahmen können die Absicht klären, und sie können auch eine fragile Illusion von Fortschritt schaffen, wenn sie ihre ursprüngliche Rechtfertigung überdauern.
• Falsche Pfade: werden nur verwendet, wenn der Pfad wirklich kein Teil des funktionalen Timings ist.
• Mehrfachzyklenpfade: werden nur verwendet, wenn die Erfassungsbeziehung tatsächlich mehrere Zyklen umfasst und dokumentiert ist.
• Ausnahmhygiene: die Menge klein halten, nach größeren RTL/Pipeline-Änderungen überprüfen und veraltete Einträge zurückziehen.
Einige der teuersten Timing-Fehler resultieren aus Ausnahmen, die einmal genau waren und dann nach einer Pipeline-Änderung stillschweigend ungenau wurden. Das Tool wird ohne Beschwerde gehorchen, was genau das ist, was diesen Fehlermodus so unangenehm macht.
Typische Fehlermuster und wie man sie effizient löst
Bestimmte Probleme wiederholen sich in Projekten, unabhängig davon, ob die Anwendung Netzwerktechnik, Vision, Steuerung oder Beschleunigung ist. Das frühe Erkennen des Musters neigt dazu, die emotionale Belastung des Debuggens zu verringern, da das Team von "Warum passiert das?" zu "Welches Handbuch gilt?" übergehen kann.
Diese Situation fühlt sich oft so an, als sei das Tool störrisch, aber die Ursachen sind in der Regel nachvollziehbar.
• Kombinatorische Tiefe: lange Pfade, die durch fehlende oder unzureichende Pipeline entstehen.
• Fanout-Druck: Hoch-Fanout-Steuerung-Netze, die von Replikation, Pufferung oder Umstrukturierung profitieren.
• Einschränkungsmodellierung: Taktdefinitionen oder -beziehungen, die falsch charakterisieren, was analysiert werden sollte.
Eine Sequenz, die in der Regel gut funktioniert, ist: das Timing-Modell validieren (Takte und Beziehungen), sich zunächst auf die am schlechtesten ausfallenden Endpunkte konzentrieren und sich dann nur dann auf architektonische Änderungen ausweiten, wenn die Pfadbeweise dies unterstützen.
Dies ist eines der demoralisiertesten Erlebnisse in der FPGA-Arbeit, hauptsächlich weil es sich anfühlt, als wäre die Realität unfair. In der Regel liegt es nur daran, dass die Simulation die gleichen Fehlermuster nicht belastet hat.
• CDC/Reset-Verhalten: Reset-Sequenzierungen und Taktdomänensprünge, die eine Simulation selten realistisch ausübt.
• I/O-Annahmen: unbeschränkte oder falsch beschränkte I/O, die marginale reale Schnittstellen produziert.
• Initialisierungsverhalten: Abhängigkeit von Anfangswerten, die nicht sauber auf das Verhalten beim Einschalten des Geräts abgebildet werden.
Teams, die stabiler werden, bringen CDC- und Reset-Strategien frühzeitig in die Entwurfsdiskussion, behandeln sie als Teil der Entwurfsarchitektur und nicht als Aufräumphase, nachdem die "wirkliche Logik" abgeschlossen ist.
Dieses Problem ist häufig, weil Platzierung und Routing scharf auf Änderungen der Netlistenstruktur reagieren, selbst wenn die funktionale Änderung geringfügig erscheint.
• Netlistenempfindlichkeit: Kleine Refaktorisierungen können Verpackungs-, Platzierungsentscheidungen und Routing-Überlastungen ändern.
• Einschränkungsdrift: Kleine XDC-Änderungen (oder fehlende Abdeckung) können zeitliche Variationen verstärken.
• Milderungsgewohnheiten: inkrementelle Implementierung, selektive Hierarchieerhaltung und stabile Einschränkungen.
Wenn Teams diese Milderungsgewohnheiten übernehmen, fühlt sich die Iteration vorhersehbarer an, was die Versuchung verringert, das Design zu früh einzufrieren aus Angst, das Timing erneut zu brechen.
Lizenzierungsüberlegungen
Lizenzierung wird oft zu einem Gesprächsthema, wenn ein Projekt auf die Geräteabdeckungsgrenzen stößt oder wenn fortgeschrittene Funktionen für einen bestimmten Arbeitsablauf benötigt werden.
• Standard: stimmt oft mit Einstiegs- und Mittelklasse-Lernboards und Basisabläufen überein.
• Unternehmenslizenz: stimmt oft mit breiterer Geräteunterstützung und erweiterten Fähigkeiten überein.
Für Teams sind floatende Lizenzen, die von einem Lizenzserver gestützt werden, oft einfacher zu skalieren als node-locke Lizenzen, insbesondere wenn Builds auf gemeinsamen Maschinen, dedizierten Build-Servern oder CI-Runnern ausgeführt werden. Viele Teams ziehen es vor, die Lizenzierung früher mit der Geräte-Roadmap abzugleichen, da Lizenzierungsüberraschungen oft auftreten, wenn der Wechsel von Geräten bereits teuer und politisch schwierig ist.
Eine konsistente Ingenieurschleife sagt tendenziell stabileren Fortschritt voraus als jede einzelne clevere Optimierung: Halten Sie Einschränkungen im Einklang mit der Realität, lesen Sie Berichte routinemäßig (auch wenn Sie es lieber nicht würden), beheben Sie die Ursachen anstatt nur Symptome zu beruhigen, und halten Sie Builds reproduzierbar. Wenn diese Schleife etabliert ist, fühlt sich Vivado weniger wie eine Black Box und mehr wie ein Instrumentenpanel an, und der Timing-Abschluss verwandelt sich von einer Last-Minute-Anstrengung in etwas, das das Team absichtlich steuern kann.
Xilinx-Portfolio und -Ökosystem

Die Auswahl unter Xilinx-Geräten verläuft tendenziell reibungsloser, wenn der Ausgangspunkt die umgebende Integration (Prozessoren, Speicherschnittstellen, Boot-Pfad und board-level Abhängigkeiten) ist und nicht nur ein Vergleich der Roh-LUT-Gesamtzahlen. Diese Rahmenbedingungen entsprechen in der Regel, wie echte Zeitpläne und echte Risiken erscheinen.
Ein diskretes FPGA passt, wenn das Team die volle Kontrolle über die Board-Architektur wünscht und die Arbeitslast zu deterministischem Hardwareverhalten bei minimaler Softwareoberfläche neigt. Ein SoC der Zynq-Klasse passt, wenn das Design von einer CPU profitiert, die nah an der Beschleunigungslogik sitzt, sodass Steuerung und Datenpfad zusammen entwickelt werden können, ohne das Board in eine Multi-Chip-Verhandlung zu verwandeln. Ein Modul im Kria SOM-Stil passt, wenn der Plan darin besteht, schnell zu arbeiten und die Unsicherheit beim Board-Start zu begrenzen, indem Rechenkapazität, Speicher und Boot-Speicher als vorqualifizierter Baustein behandelt werden.
Discrete FPGA passt tendenziell für:
• maximale Kontrolle über das Board-Design
• deterministische Pipelines mit begrenzter Softwareabhängigkeit
Zynq SoC passt tendenziell für:
• enge CPU+Beschleuniger-Kopplung
• vereinheitlichte Rechen-/Steuerung auf einem Gerät
• iterative HW/SW-Evolution
Kria SOM passt tendenziell für:
• kürzere Zeit bis zum Produkt
• reduzierte Board-level Exposition durch die Verwendung eines validierten Rechen-Subsystems
Normale FPGAs landen oft gut, wenn das Problem durch den Druck auf den Timing-Abschluss, ungewöhnliche I/O-Anforderungen oder Streaming-Pipelines, die sich am besten als festverdrahtete Hardware verhalten, getrieben wird. Vorhersehbare Latenzen und strukturierte Datenpfade verbessern oft Steuerung, Verifizierung und Debugging, insbesondere wenn die Architektur gut organisiert bleibt.
Standalone-Geräte treten häufig auf in:
• Sensornutzung
• Motorsteuerung
• Paketverarbeitung mit moderater Rate
• Protokollbrückung
Im Feld ist eine wiederkehrende Quelle der Frustration nicht das RTL selbst, sondern die angrenzenden Board-Verpflichtungen, die leise ankommen und dann den kritischen Pfad dominieren. Stromschienen, Konfigurations- und Boot-Strategien, Takt-Generierung, externes Speichergestaltungs (wenn vorhanden) und Debug-Zugriff können zu den Einschränkungen werden, die das gesamte Produkt prägen. Eine praktische Faustregel besagt, dass je einfacher die externe Speichergeschichte ist und je weniger Hochgeschwindigkeits-Transceiver beteiligt sind, desto befriedigender wird die Standalone-FPGA-Erfahrung. Sobald externes DDR und mehrstufige Boot-Flows unvermeidbar werden, fühlt sich der Integrationsreiz eines SoC oder eines Moduls weniger wie ein Merkmal und mehr wie eine Erleichterung an.
Kostenoptimierte Familien zielen im Allgemeinen auf eine gemessene Mischung aus LUTs, BRAM und DSP unter restriktiven Leistungsbudgets ab. Sie treten häufig in Produkten auf, in denen das Ingenieurteam respektable Fähigkeiten ohne die Kosten für das Board und die thermischen Aufwendungen, die mit extremen Schnittstellen verbunden sind, wünscht.
Häufige Einsatzgebiete sind:
• Embedded Control
• Aggregation von I/O in mittlerem Bereich
• Signalverarbeitung mit moderater Geschwindigkeit
Der Vorteil liegt nicht nur im Stückpreis, die Teams schätzen oft, dass diese Teile es einfacher machen, innerhalb der thermischen Grenzen zu bleiben, ohne auf aggressive Kühlung zurückgreifen zu müssen, und sie können verhindern, dass die PCB zu einem Hochgeschwindigkeitslayoutprojekt eskaliert. Gleichzeitig bringen Feld-Bauten regelmäßig eine leicht unangenehme Lektion mit sich: Ein kostengünstigeres Gerät kann höhere Gesamtausgaben auslösen, wenn es zu Kompromissen in der Designphase zwingt. Wenn die Timing-Marge dünn ist, können kleine Anpassungen, eine Änderung des I/O-Standards, eine Anpassung der Takt-Routing, eine Änderung des Layouts, eine Kettenreaktion auf Prüfungsaufwand und Zeitdruck auslösen. Bei diesen Geräten sparen Teams normalerweise Zeit, indem sie die Planung der Takt-Domänen, die CDC-Strategie und das Zurücksetzenverhalten frühzeitig festlegen, anstatt zu hoffen, dass späte Mikro-Optimierungen den Plan retten.
Zynq SoCs
Zynq-Geräte kombinieren ARM-Verarbeitung mit programmierbarer Logik, was es dem Design ermöglicht, sich auf eine Weise in Steuerplanesoftware und Datenplanebeschleunigung aufzuteilen, die für viele Produktteams natürlich erscheint. Dies verbessert nicht nur den Komfort, sondern verändert auch den Arbeitsablauf. Teams können mit einem Software-ersten Referenzmodell für funktionale Sicherheit beginnen und dann heiße Pfade in Hardware migrieren, wenn Durchsatz- und Latenzanforderungen weniger verhandelbar werden.
In Einsätzen, die gut altern, "ersetzt" die CPU selten Hardware, sie stabilisiert eher das Produkt. Der Prozessor übernimmt oft Konfiguration, Telemetrie, Feldaktualisierungen, Sicherheitsrichtlinien und Edge-Konnektivität, während das Gewebe deterministische Pipelines betreibt. Diese Trennung kann für die Wartenden emotional beruhigend sein: Software absorbiert Veränderungen, Hardware bleibt stabil und Releases fühlen sich weniger riskant an.
Die CPU trägt üblicherweise:
• Konfiguration
• Telemetrie
• Aktualisierungen
• Sicherheitsrichtlinien
• Edge-Konnektivität
Das Gewebe trägt üblicherweise:
• deterministische Streaming-Pipelines
• stabile Beschleuniger
• latenzsensitive Datenpfade
Mit steigendem Rechendichte und zunehmend anspruchsvollen Schnittstellen reduzieren Teile im Zynq UltraScale+ Stil die Board- und Systemkomplexität, indem sie CPU-Kerne, DDR-Controller und Hochgeschwindigkeitsverbindungen näher an das Gewebe heranführen. Dies wird in Designs attraktiv, die sowohl Echtzeitsicherheit als auch ein fähiges Softwareumfeld benötigen, insbesondere wenn die Arbeitslast eine Mischung und kein einzelner klarer Kernel ist.
Häufige Anwendungsfälle sind:
• Edge-Analytik
• Multi-Sensor-Fusion
• gemischte Echtzeit-Plus-AI-Pipelines
Ein Detail, das erfahrene Teams lernen zu respektieren, ist, dass "mehr Gewebe" nicht automatisch in "mehr gelieferten Leistung" umschlägt. Projekte stoßen oft auf Gedächtnisbandbreite-Obergrenzen, bevor sie DSPs oder LUTs erschöpfen. Designs, die frühzeitig über DMA-Topologie, Pufferstrategie und Cache-Kohärenz-Erwartungen entscheiden, tendieren dazu, stabile Leistung mit weniger Störungen zu erreichen als Designs, die Entscheidungen über die Datenbewegung bis zur späten Integration aufschieben.
Partitionierung geht selten darum, ob etwas beschleunigt werden könnte; es geht eher darum, ob sich die Beschleunigung angesichts des Verifizierungsaufwands, der Komplexität von Treibern und Laufzeit sowie der Häufigkeit, mit der sich die Logik ändern soll, auszahlt. Teams fühlen hier oft einen Wettbewerb: Zu viel in die Hardware zu schieben, kann die Iteration verlangsamen, während zu viel auf der CPU zu einem dauerhaft fast erreichten Durchsatzziel führen kann.
Arbeitslasten, die häufig länger als erwartet auf der CPU bleiben, sind:
• schnell wechselnde Logik
• komplexes parsing-intensives Verhalten
• Funktionen mit schnellen Iterationszyklen
Arbeitslasten, die oft frühzeitige Gewebe-Beschleunigung belohnen, sind:
• stabile Algorithmen
• rechenintensive Kerne
• streamfreundliche Datenpfade
Ein pragmatisches Muster besteht darin, mit einem kleinen, End-to-End-Slice zu beginnen, oft einer einfachen DMA-Schleife plus einem minimalen Beschleuniger, bevor der gesamte Funktionsumfang aufgebaut wird. Dieses begrenzte Prototyp tendiert dazu, die Integrationsprobleme ans Licht zu bringen, die sonst spät und kostspielig auftreten: Interruptverhalten, Pufferanpassung, Cache-Wartungskosten und Durchsatzobergrenzen, die nur unter kontinuierlicher Last auftreten.
Kria SOMs und modulare Plattformen
Kria SOMs bündeln Rechenleistung, Speicher und Boot-Speicher in einem einsatzbereiten Subsystem und verlagern den Aufwand von der Board-Integration hin zur Anwendungsentwicklung. Teams mögen diesen Ansatz oft, weil er Unsicherheiten verringert: Signalintegrität, DDR-Routing, Power-Sequenzierung und Boot-Zuverlässigkeit sind bereits validiert, was frühe Demos weniger fragil und die Planung weniger spekulativ erscheinen lässt.
Der Ansatz funktioniert besonders gut, wenn die Differenzierung in Algorithmen, I/O-Topologie und Bereitstellungszuverlässigkeit statt in einem maßgeschneiderten Rechenboard liegt. Dadurch kann auch der Reibungswiderstand zwischen Teams verringert werden: Hardware-, Firmware- und Anwendungsarbeiten können parallel mit weniger Momenten der "von der Integration blockiert" bewegt werden.
Validierte SOM-Integration umfasst üblicherweise:
• Signalintegrität
• DDR-Routing
• Power-Sequenzierung
• Boot-Zuverlässigkeit
Teams können den Aufwand auf folgende Punkte umverteilen:
• Differenzierung des Trägersystems
• Firmware-Integration
• Anwendungsverhalten
• Bereitstellungsabsicherung
Ein SOM hat oft höhere Kosten pro Einheit als ein vollständig maßgeschneidertes Board, dennoch kann die Gesamtkosten des Programms sinken, wenn die Zeitpläne eng sind oder das Risiko der Herstellungsausbeute unangenehm ist. Der weniger offensichtliche Gewinn ist die Vorhersehbarkeit des Lebenszyklus: Mit einem Modul kann Rechnen manchmal wie ein austauschbares Element über Produktvarianten behandelt werden, was den Aufwand für Neugestaltungen verringert, wenn sich die Anforderungen mitten im Prozess ändern.
Der beruhigendste Schritt ist, frühzeitig zu validieren, dass der thermische Spielraum, die I/O-Exposition und die Speicherbandbreite des SOMs tatsächlich mit der beabsichtigten Arbeitslast übereinstimmen, anstatt sich auf eine Spezifikationsblattlesung zu verlassen. Wenn die Anwendung bandbreitengebunden wird, fühlt sich das nachträgliche Feintuning oft so an, als ob man gegen eine verschlossene Tür drückt; die Diskrepanz zwischen der Nachfrage nach dem Beschleuniger und dem Speichersubsystem des Moduls dominiert einfach.
Frühzeitige Anpassungsprüfungen umfassen üblicherweise:
• thermischen Rahmen
• exponierte I/O
• nachhaltige Speicherbandbreite im Vergleich zur Arbeitslastanforderung
AI-Bereitstellung im Ökosystem
Vitis AI hilft dabei, trainierte Modelle in FPGA-basierte Inferenzdesigns umzuwandeln, indem niedrigpräzise Formate verwendet werden, oft INT8, und sie für DPU-Stil-Architekturen kompiliert werden. Dies bestätigt schnell, ob ein Modell auf der FPGA-Plattform funktionieren kann. Die tatsächliche Leistung hängt jedoch oft stark vom umgebenden Systemdesign ab, insbesondere von der Datenbewegung und dem Speicherhandling.
Der End-to-End-Durchsatz wird typischerweise davon bestimmt, wie konsistent das System die DPU versorgen kann. Batch-Strategie, Tensor-Layout, DMA-Planung, Double-Buffering und Speicherplatzierung entscheiden oft mehr über die gelieferten FPS als die rechnerischen Überschriften. Teams, die die DPU wie einen stetigen Streaming-Verbraucher betrachten, mit sorgfältig gestaffelten Buffern, vermeiden tendenziell die häufige Enttäuschung über beeindruckende theoretische TOPS, aber enttäuschende Ergebnisse auf Systemebene.
Leistungsstärkende Regler umfassen typischerweise:
• Batch-Strategie
• Tensor-Layout
• DMA-Planung
• Double-Buffering
• Speicherplatzierung
In Implementierungen summieren sich geringfügige Auswahlentscheidungen auf eine Weise, die von labormikrobenchmarks schwer vorherzusagen sein kann. Fehlalignierte Puffer können leise die effektive Bandbreite reduzieren. Übermäßige Cache-Wartung kann CPU-Zeit aufzehren und Jitter verursachen. Kopierlastige Pipelines können einen Großteil des durch Quantisierung gewonnenen Vorteils zunichte machen. Ein geerdeter Ansatz besteht darin, Bandbreite und Latenz an jeder Grenze zu messen und dann die Anstrengung auf die Grenze zu konzentrieren, die derzeit am engsten ist.
Nützliche Messgrenzen umfassen:
• Sensor zu DDR
• DDR zu Beschleuniger
• Beschleuniger zu Nachbearbeitung
Ein hilfreiches mentales Modell ist, die KI-Pipeline als ein eingeschränktes Fließnetzwerk zu betrachten. Mit dieser Rahmenbedingung wird die Auswahl des Geräts weniger zu einer Jagd nach der größten Rechenanzahl und mehr zu einer Auswahl der Option, die den dominierenden Engpass entspannt und das Pipeline-Verhalten vorhersagbar hält.
Ecosystem und Ermöglichung
Das Xilinx-Ökosystem reicht über Silizium hinaus in die umgebende Ermöglichung, die die Teams in Bewegung hält: Toolchains, IP, Referenzdesigns, Partnerboards und Schulungsressourcen. In akademischen Umgebungen wird das University Program oft geschätzt, weil es wiederkehrende Einrichtungsprobleme, den Zugriff auf Tools, die Verfügbarkeit von Boards und die Laborstruktur reduziert, sodass frühe Fortschritte weniger wahrscheinlich durch Umweltprobleme als durch das Erlernen der tatsächlichen Ingenieurarbeit ins Stocken geraten.
Die Komponenten des Ökosystems umfassen:
• Toolchains (Vivado, Vitis)
• IP-Kataloge
• Referenzdesigns
• Partnerboards
• Schulungsprogramme
• Ressourcen des University Program
Sobald die Einarbeitungsfriktion reduziert ist, können Lernende ihre Energie auf die Gewohnheiten verwenden, die sich direkt in professionelle Arbeit übersetzen: Timing-Abschluss-Routinen, Pipeline-Disziplinen, Verifikationsstrategien und Urteile zur Hardware-/Software-Co-Design. Diese Fähigkeiten zeigen tendenziell ihren Wert während der Integration, wenn die Ergebnisse mehr von der Iterationsgeschwindigkeit und der Systemkohäsion geprägt sind als von einem isolierten Kernel-Benchmark.
Übertragbare Fähigkeiten umfassen:
• Timing-Abschlussgewohnheiten
• Pipeline-Disziplin
• Verifikationsstrategie
• Hardware-/Software-Co-Design
Ein Auswahlprinzip, das über das gesamte Angebot hinweg konstant bleibt
Ein zuverlässiger Auswahlansatz beginnt bei den Systemanforderungen und nicht bei den Marketingstufen. Teams treffen in der Regel klarere Entscheidungen, wenn sie die Betriebsziele und Projektrealitäten upfront festhalten und dann die Integrationsstufe, FPGA, Zynq SoC oder SOM auswählen, die die größten Unsicherheitsquellen für ihr spezifisches Programm reduziert. Dies führt tendenziell zu Entscheidungen, die sich Monate später besser anfühlen, wenn Integration und Iterationsgeschwindigkeit wichtiger sind als ein Vergleich der Teile auf dem Papier.
Früh zu definierende Einschränkungen umfassen:
• Latenz-Ziele
• Nachhaltige Bandbreitenbedürfnisse
• Schnittstellenanforderungen
• Thermische Grenzen
• Aktualisierungsrhythmus
• Verifikationsbudget
In vielen Programmen ist die Option, die die Datenbewegung einfach und den Entwicklungszyklus straff hält, oft diejenige, die am besten altert, selbst wenn ihr Preis pro Einheit auf den ersten Blick nicht am attraktivsten ist.
Schlussfolgerung
Das Lernen von Xilinx FPGA-Design wird einfacher, wenn jedes Projekt einem stabilen und wiederholbaren Prozess folgt. Starke Ergebnisse hängen von sauberem HDL, korrekten Einschränkungen, sorgfältigen Timing-Prüfungen, Simulation und realer Hardwarevalidierung ab. Wenn Anfänger mit einfachen Designs beginnen und gute Debugging-Gewohnheiten entwickeln, können sie zuverlässige FPGA-Fähigkeiten für fortgeschrittene digitale Systeme entwickeln.
Häufig gestellte Fragen [FAQ]
1. Warum haben FPGA-Anfänger oft Probleme, selbst wenn ihr HDL-Code in der Simulation logisch korrekt erscheint?
Viele frühe FPGA-Probleme werden nicht durch das RTL selbst verursacht, sondern durch die Lücke zwischen Simulationseinstellungen und dem Verhalten der physischen Hardware. Simulationen verstecken normalerweise Probleme, die mit Taktschaltungen, Reset-Timings, I/O-Standards, Metastabilität und Timing-Abschluss zusammenhängen. Ein Design kann perfekt simuliert werden und dennoch auf der Hardware fehlschlagen, weil die FPGA-Tools Uhren unterschiedlich interpretieren, Einschränkungen unvollständig sind oder asynchrone Eingaben falsch behandelt werden.
2. Warum werden Timing-Einschränkungen als integraler Bestandteil des FPGA-Designs betrachtet und nicht als letzter Optimierungsschritt?
Timing-Einschränkungen definieren, wie die FPGA-Tools Uhren, I/O-Timings, generierte Uhren und asynchrone Domänen interpretieren. Ohne genaue Einschränkungen kann Vivado das Design mit falschen Annahmen optimieren, was zu irreführenden Timing-Berichten und instabilem Hardware-Verhalten führt. Viele FPGA-Fehler treten selbst auf, wenn die Logik korrekt ist, weil Uhren nicht richtig deklariert wurden, I/O-Timings ignoriert wurden oder Ausnahmen zu weit gefasst angewendet wurden. In der Praxis fungieren Einschränkungen als formale Beschreibung der Designabsicht, die es den Tools ermöglichen, Hardware zu erstellen, die dem tatsächlichen elektrischen Verhalten entspricht.
3. Warum erfordert das Debugging von FPGAs oft sowohl Simulation als auch On-Chip-Tools wie ILA?
Simulation ist sehr effektiv, um funktionale Fehler zu erkennen, kann jedoch die realen Hardwareeffekte wie Jitter, asynchrone Eingaben, boardweite Verzögerungen, Metastabilität und Spannungsschwankungen nicht vollständig reproduzieren. On-Chip-Debugging-Tools wie der Integrated Logic Analyzer (ILA) bieten Sichtbarkeit in interne FPGA-Signale, während das System unter realen Bedingungen betrieben wird. Dies ermöglicht das Erfassen tatsächlicher Zustandsübergänge, FIFO-Verhalten, Handshakes und Timing-Beziehungen direkt im Gerät. Die Kombination von Simulation mit ILA-Debugging schafft ein umfassenderes Verständnis dafür, warum die Hardware vom erwarteten Verhalten abweicht.
4. Warum bevorzugen erfahrene FPGA-Ingenieure disziplinierte, wiederholbare Arbeitsabläufe anstelle ständig wechselnder Projektkonfigurationen?
Wiederholbare Arbeitsabläufe verringern die Unsicherheit und erleichtern das Isolieren von Fehlern. Die Verwendung derselben Entwicklungsplatine, Taktstruktur, Rücksetzstrategie und Projektschablone ermöglicht es Ingenieuren, sich auf die entwickelte Logik zu konzentrieren, anstatt immer wieder die Umgebung selbst zu debuggen. FPGA-Projekte beinhalten viele miteinander interagierende Variablen, einschließlich Einschränkungen, Taktsteuerung, Syntheseverhalten und boardweite Konfiguration. Wenn zu viele Variablen gleichzeitig geändert werden, wird das Debuggen unvorhersehbar und emotional belastend. Stabile Arbeitsabläufe verbessern das Vertrauen, da Änderungen auf spezifische Designentscheidungen zurückgeführt werden können, anstatt auf unbekannte Umgebungsunterschiede.
5. Warum ist das FPGA-Hardware-Design grundsätzlich anders als traditionelles Software-Programmieren?
Software führt Anweisungen sequenziell aus, während FPGA-Hardware durch gleichzeitig laufende logische Strukturen operiert. HDL beschreibt das physische Hardwareverhalten und nicht den prozeduralen Ausführungsfluss. Anfänger erwarten oft ein softwareähnliches Verhalten und sind dann verwirrt, wenn mehrere Hardwareblöcke zur gleichen Taktflanke parallel reagieren. Das FPGA-Design legt daher den Schwerpunkt auf Pipelines, Timing-Beziehungen, Synchronisation, Ressourcenabbildung und Takt-Domänenverhalten anstelle von alleiniger Anweisungsreihenfolge. Das Verständnis von Parallelität ist einer der wichtigsten mentalen Wechsel in der FPGA-Entwicklung.
6. Warum können kleine RTL-Änderungen plötzlich erhebliche Timing-Abschlussprobleme in FPGA-Projekten verursachen?
Das Timing-Verhalten von FPGAs hängt stark von der Platzierung, der Routing-Überlastung, dem Fächerverhalten, den Taktbeziehungen und der physischen Ressourcennutzung ab. Selbst kleine RTL-Änderungen können beeinflussen, wie die Synthese- und Routing-Tools Logik über das Gerät abbilden. Eine scheinbar harmlose Änderung kann den Routing-Druck erhöhen, kombinatorische Pfade verlängern oder Platzierungsentscheidungen in einer Weise beeinflussen, die die Timing-Marge erheblich reduziert. Diese Empfindlichkeit wird stärker, je höher die Auslastung ist, insbesondere wenn Designs die Routing- oder Taktgrenzen erreichen.
7. Warum werden FPGA-Projekte häufig durch boardweite Realitäten eingeschränkt, anstatt nur durch die Komplexität des RTL?
Wenn FPGA-Systeme wachsen, treten Herausforderungen im Zusammenhang mit der Leistungssequenzierung, dem DDR-Layout, der Taktgenerierung, dem thermischen Verhalten, der Signalintegrität und der Transceiver-Router oft in den Vordergrund der Entwicklungszeit. Der RTL kann korrekt funktionieren, während die umgebende Hardware-Infrastruktur Instabilität oder Integrationsfehler einführt. Ingenieure entdecken häufig, dass die Entscheidungen zum Platinen-Design, die Rücksetzsequenzierung und das Verhalten der Speicher-Schnittstelle den Gesamterfolg des Projekts mehr prägen als das HDL selbst. Dies gilt insbesondere in Hochgeschwindigkeits-Systemen, die externe DDR-Speicher und SERDES-Schnittstellen verwenden.
8. Warum bewerten viele FPGA-Teams Toolchains ebenso ernsthaft wie die FPGA-Hardware selbst?
Die FPGA-Toolchain beeinflusst direkt die Kompilierzeit, die Stabilität des Timing-Closures, die Effizienz des Debuggings, die CI-Integration und die allgemeine Produktivität der Ingenieure. Langsame oder inkonsistente Implementierungsergebnisse können die Iterationszeit und den Zeitdruck dramatisch erhöhen. Teams bewerten oft die Synthesegüte, die Klarheit der Timing-Berichte, die Debug-Instrumentierung und die Reproduzierbarkeit, bevor sie sich für eine Plattform entscheiden. In echten Entwicklungsumgebungen sind vorhersehbare Builds und stabiles Timing-Closure oft wichtiger als isolierte Haupt-FPGA-Spezifikationen.
9. Warum reduzieren Zynq SoCs und Kria SOM-Plattformen die Integrationskomplexität im Vergleich zu eigenständigen FPGAs?
Zynq SoCs kombinieren ARM-Prozessoren und programmierbare Logik in einem Gerät, was die Kommunikation zwischen Software und Hardwarebeschleunigung vereinfacht. Kria SOMs gehen noch weiter, indem sie Speicher, Boot-Speicher, Stromsequenzierung und validierte Hardware in ein vorqualifiziertes Modul integrieren. Diese Ansätze reduzieren Risiken, die mit dem DDR-Routing, der Boot-Zuverlässigkeit, dem Stromversorgungsdesign und dem Board-Start verbunden sind. Infolgedessen können sich die Teams stärker auf das Anwendungsverhalten und weniger auf Herausforderungen bei der niedrigstufigen Hardwareintegration konzentrieren.
10. Warum hängt der erfolgreiche FPGA-basierte AI-Einsatz stark von der Datenbewegung ab und nicht nur von der Leistung des Beschleunigers?
AI-Beschleuniger wie DPUs können einen hohen theoretischen Berechnungsdurchsatz bieten, aber die Leistung in der realen Welt wird oft durch den Speicherbandbreite, die DMA-Planung, das Puffermanagement und die Effizienz der Tensorbewegung eingeschränkt. Schlecht optimierte Datenpipelines können den Beschleuniger hungern lassen und die effektiven FPS trotz starker Rechenkapazität drastisch reduzieren. Erfolgreiche FPGA-AI-Systeme konzentrieren sich daher stark auf Double-Buffering, DMA-Topologie, Batch-Strategie, Speicherplatzierung und nachhaltigen Datenfluss zwischen Sensoren, DDR-Speicher, Beschleunigern und Nachbearbeitungsphasen.
Verwandter Blog
-
Wie viele Nullen in einer Million, Milliarden, Billionen?
![Wie viele Nullen in einer Million, Milliarden, Billionen?]()
2024/07/29
Millionen repräsentieren 106, eine leicht griffbare Figur im Vergleich zu alltäglichen Gegenständen oder jährlichen Gehältern. Milliarden, entspr... -
IRLZ44N MOSFET -Datenblatt, Schaltung, Äquivalent, Pinout
![IRLZ44N MOSFET -Datenblatt, Schaltung, Äquivalent, Pinout]()
2024/08/28
Der IRLZ44N ist ein weit verbreiteter N-Kanal-Power-MOSFET.Es ist bekannt für seine hervorragenden Schaltkapazitäten und eignet sich sehr für zahlr... -
Batteriestemperatur zu niedrig, das Laden gestoppt.Wie repariere ich es?
![Batteriestemperatur zu niedrig, das Laden gestoppt.Wie repariere ich es?]()
2024/10/6
Das Ladeproblemen von Mobiltelefonen sind häufig, können jedoch effektiv verwaltet werden.Die Temperatur spielt eine große Rolle bei der Batterieff... -
BC547 Transistor umfassender Leitfaden
![BC547 Transistor umfassender Leitfaden]()
2024/07/4
Der BC547 -Transistor wird üblicherweise in einer Vielzahl elektronischer Anwendungen verwendet, die von grundlegenden Signalverstärkern bis hin zu ... -
Umfassende Anleitung zum SCR (Siliziumgesteuerte Gleichrichter)
![Umfassende Anleitung zum SCR (Siliziumgesteuerte Gleichrichter)]()
2024/04/22
Siliziumkontrollierte Gleichrichter (SCR) oder Thyristoren spielen aufgrund ihrer Leistung und Zuverlässigkeit eine entscheidende Rolle in der Energi... -
LR621, SR621SW, 364, AG1 -Batterieäquivalente und Ersatz
![LR621, SR621SW, 364, AG1 -Batterieäquivalente und Ersatz]()
2024/07/15
Die Batterien von LR621- und SR621SW -Tasten sind in kompakten elektronischen Geräten wie Uhren, kleinen Spielzeugen, Taschenrechnern und Fernschlüs... -
Ein vollständiger Leitfaden für Multiplexer und ihre Rolle in digitalen Systemen
![Ein vollständiger Leitfaden für Multiplexer und ihre Rolle in digitalen Systemen]()
2025/09/20
Multiplexer sind Komponenten in digitalen Systemen, mit denen mehrere Eingangssignale unter Verwendung binärer Logik- und Kontrollsignale in eine ein... -
Grundlagen von Op-Ampere-Schaltungen
![Grundlagen von Op-Ampere-Schaltungen]()
2023/12/28
In der komplizierten Welt der Elektronik führt uns eine Reise in ihre Geheimnisse ausnahmslos zu einem Kaleidoskop aus exquisiten und komplexen Schal... -
Vergleich der Unterschiede und Anwendungen von NMOs und PMOS
![Vergleich der Unterschiede und Anwendungen von NMOs und PMOS]()
2024/11/15
Das Verständnis der Unterschiede zwischen NMOS- und PMOS -Transistoren ist wichtig für die Gestaltung effizienter Schaltkreise.NMOs (N-Type-Metallox... -
CR2450 gegen CR2032 Vergleich: Alles was Sie wissen müssen
![CR2450 gegen CR2032 Vergleich: Alles was Sie wissen müssen]()
2025/09/15
Button -Batterien wie CR2450 und CR2032 führen viele alltägliche Elektronik aus, von Uhren und Fernbedienungen bis hin zu medizinischen und industri...









Heiße Teile
- AMK063F104ZP-F
- MB29F400TC-90PFTN
- 0402ZC223JAT2A
- LM2733YMF
- PE-68881
- M30626FJPGP#U5C
- H8TBR00U0MLR
- MC41P6104M
- AD7992BRMZ-1
- S29PL064J70BFW123E
- BUF04701AIPW
- LTC2053CMS8#PBF
- A6S-4102-H
- 04023A120DAT2A
- C0603CH1E090D030BA
- A2C37376
- MC14LC5447DW
- C3216JB2A334M130AA
- ABLNO-V-96.000MHZ-T2
- C2012CH2W151K060AA
- GRM1885C1H1R6CZ01D
- GJM0335C0J220GB01D
- IT8709E-EXS
- C2012X6S0G476M125AC
- TPS53640RSBT
- AN31910A-VF
- TG74-1406N1
- MCIMX6L2DVN10AB
- SI3000-C-FSR
- W987D6HBGX7E
- LMV431ACM5/NOPB
- DAC7724UB
- PIC24EP512GU810-I/PF
- T495B106K016ATE800
- 1DI30F100
- 89HPES4T4ZBBCG8
- 06031C331KAT2A
- OPA337UA
- T491D106K025AT4280
- SI7113ADN-T1-GE3
- T491A225M016AT4165
- MAX942EUA
- MAX6006BEUR+T
- T491B475K020AT4153
- T491A106K010AG
- T89C51IC2-SLSIL
- HSMP3811
- K4S561632A-TL75
- DX121-C6AHA24DF-LDT
- DE1E3RA222MA4BN01F