- Deutsch
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Was ist eine NPU und wie funktioniert sie in KI-Geräten?
Katalog

Was ist eine NPU?
Eine Neural Processing Unit (NPU) ist ein spezialisierter Prozessor, der Aufgaben der künstlichen Intelligenz effizienter bewältigen kann als ein Allzweckprozessor.Seine Hauptaufgabe besteht darin, neuronale Netzwerkoperationen zu beschleunigen, die in Funktionen wie Bilderkennung, Sprachverarbeitung, Objekterkennung und Echtzeit-KI-Inferenz verwendet werden.Im Gegensatz zu einer CPU, die für die Verwaltung vieler verschiedener Rechenaufgaben ausgelegt ist, konzentriert sich eine NPU auf KI-bezogene Berechnungen.Es ist für die gleichzeitige Verarbeitung großer Datenmengen optimiert und eignet sich daher für Arbeitslasten, die eine schnelle Mustererkennung und Entscheidungsfindung erfordern.In modernen Geräten helfen NPUs dabei, KI-Funktionen direkt auf lokaler Hardware auszuführen, anstatt vollständig von Cloud-Servern abhängig zu sein.Dadurch können Smartphones, Smart-Kameras, Roboter, Fahrzeuge und Edge-Geräte schneller reagieren und gleichzeitig weniger Strom verbrauchen.Aus diesem Grund sind NPUs zu einem wichtigen Bestandteil moderner intelligenter Systeme geworden.
Kernarchitektur und Verarbeitungsmodule einer NPU
Eine NPU besteht aus mehreren spezialisierten Hardwaremodulen, die zusammenarbeiten, um Arbeitslasten neuronaler Netzwerke schnell und effizient zu verarbeiten.Anstatt jeden Vorgang über einen Allzweckprozessor zu leiten, wird die Arbeitslast auf dedizierte Hardwareblöcke aufgeteilt, die kontinuierlich Daten parallel verarbeiten.Diese Struktur verbessert die KI-Inferenzgeschwindigkeit, reduziert unnötige Datenbewegungen, senkt den Stromverbrauch und trägt zur Aufrechterhaltung einer effizienten Speichernutzung bei.
Während der KI-Verarbeitung durchlaufen Daten mehrere Stufen innerhalb des Prozessors.Eingabedaten gelangen zunächst in die Rechenpipeline, wo umfangreiche mathematische Operationen ausgeführt werden.Zwischenergebnisse durchlaufen dann die Aktivierungsverarbeitung, Tensorbeschleunigung, bildbezogene Operationen und Speicheroptimierungshardware, bevor die endgültige Ausgabe erzeugt wird.Da diese Module in einer koordinierten Reihenfolge zusammenarbeiten, kann die NPU auch bei der Ausführung großer neuronaler Netzwerkmodelle einen hohen Durchsatz aufrechterhalten.
Kern-Computing- und Aktivierungsmodule
Die wichtigste Rechenmaschine innerhalb einer NPU ist die Multiply-Accumulate (MAC)-Einheit.Die meisten Arbeitslasten neuronaler Netzwerke führen wiederholt Multiplikationen und Additionen über sehr große Datensätze durch, sodass diese Hardware den Großteil der KI-Berechnungen während der Inferenz übernimmt.Wenn Eingabedaten in ein neuronales Netzwerk gelangen, werden Werte mit gespeicherten Gewichtswerten multipliziert und dann addiert, um neue Ausgaben zu generieren.Dieser Prozess wiederholt sich kontinuierlich über viele Schichten des neuronalen Netzwerks.
Moderne NPUs enthalten oft Hunderte oder Tausende gleichzeitig arbeitende MAC-Einheiten.Anstatt jeweils einen Vorgang zu berechnen, verteilt die Hardware die Arbeitslast auf viele parallele Ausführungspfade.Große Mengen an KI-Daten werden gemeinsam durch den Prozessor geleitet, was die Inferenzgeschwindigkeit erheblich verbessert und gleichzeitig die Latenz niedrig hält.In Bilderkennungssystemen beispielsweise scannen MAC-Einheiten wiederholt Pixelgruppen und kombinieren Filterwerte, um Kanten, Texturen, Formen und Muster zu erkennen.In Sprachmodellen führt dieselbe Hardware umfangreiche Vektor- und Matrixoperationen aus, um Token und Beziehungen zwischen Wörtern zu verarbeiten.
Nachdem diese mathematischen Berechnungen abgeschlossen sind, werden die Ergebnisse in das Aktivierungsfunktionsmodul verschoben.Neuronale Netze sind auf nichtlineare Aktivierungsfunktionen angewiesen, um komplexe Beziehungen innerhalb von Daten zu verarbeiten.Ohne Aktivierungsverarbeitung würde das Netzwerk nur einfache lineare Berechnungen durchführen und könnte fortgeschrittene KI-Aufgaben nicht effektiv bewältigen.
Dieses Modul führt Funktionen wie ReLU, Sigmoid und Tanh direkt in der Hardware aus.Eingehende Werte werden entsprechend der ausgewählten Aktivierungsregel schnell transformiert.ReLU entfernt beispielsweise negative Werte und behält gleichzeitig positive Ausgaben bei, wodurch sich das Netzwerk bei der Inferenz auf stärkere Merkmalssignale konzentrieren kann.Da die Aktivierungsverarbeitung auf jeder Ebene des neuronalen Netzwerks wiederholt erfolgt, trägt spezielle Beschleunigungshardware dazu bei, Verzögerungen zu reduzieren und eine Überlastung der Hauptrecheneinheiten zu verhindern.
Tensor- und räumliche Datenverarbeitungsmodule
NPUs umfassen auch spezielle Hardware für die Handhabung von Tensoroperationen und die Verarbeitung räumlicher Daten.Fast jedes moderne KI-Modell basiert auf Tensoren, mehrdimensionalen Datenstrukturen, die zum Organisieren von Informationen über Dimensionen wie Breite, Höhe, Kanäle, Merkmalsebenen und Stapel hinweg verwendet werden.Während der Inferenz werden große Mengen an Tensordaten kontinuierlich zwischen den Schichten des neuronalen Netzwerks verschoben.
Die Tensor Acceleration Unit verarbeitet diese Tensorstrukturen direkt in der Hardware.Operationen wie Tensormultiplikation, Umformung, Transformation und Akkumulation werden viel schneller ausgeführt als auf Allzweckprozessoren.Diese dedizierte Beschleunigung wird besonders wichtig in Transformatorarchitekturen, Computer-Vision-Systemen, großen Sprachmodellen und Echtzeit-KI-Anwendungen, die einen sehr hohen Durchsatz erfordern.
Neben der Tensorverarbeitung enthalten NPUs auch Module, die für 2D- und Geodatenoperationen konzipiert sind, die häufig in Bild- und Video-Workloads verwendet werden.Computer-Vision-Systeme ändern ständig die Größe, organisieren, filtern und verschieben große Mengen an Pixeldaten, bevor eine tiefergehende KI-Analyse beginnt.Die getrennte Bearbeitung dieser Aufgaben verbessert die Effizienz und verringert den Druck auf die Hauptrechner-Engine.
Während der Bildverarbeitung verwaltet die Hardware Vorgänge wie Downsampling, Feature-Map-Bewegung, Bildkopieren, Größenänderung, Zuschneiden und räumliche Datenübertragung.Beispielsweise können von einer Kamera aufgenommene hochauflösende Videos zunächst in der Größe geändert und neu organisiert werden, bevor sie in die Pipeline des neuronalen Netzwerks gelangen.Dadurch wird die Rechenlast reduziert und gleichzeitig wichtige visuelle Informationen erhalten, die für die Objekterkennung und Szenenanalyse erforderlich sind.
Speicheroptimierungs- und Datenkomprimierungsmodule
Moderne KI-Modelle benötigen große Mengen an Speicher, um Gewichte, Tensoren und Zwischendaten neuronaler Netzwerke zu speichern.Die ständige Übertragung dieser Informationen zwischen Speicher und Computerhardware erhöht die Bandbreitennutzung, Latenz und den Stromverbrauch.Um diesen Overhead zu reduzieren, enthalten NPUs dedizierte Datenkomprimierungs- und Dekomprimierungsmodule.
Bevor Daten im Speicher gespeichert werden, werden wiederholte Muster und Gewichtswerte in kleinere Formate komprimiert.Während der Ausführung werden die komprimierten Informationen schnell wiederhergestellt und direkt an die Rechenpipeline gesendet.Dies reduziert den Speicherverkehr und ermöglicht, dass mehr KI-Daten im lokalen Hochgeschwindigkeitsspeicher näher am Prozessor verbleiben.
Fortschrittliche Komprimierungsmethoden können die Modellgröße häufig um ein Vielfaches reduzieren und dabei nahezu die gleiche Inferenzgenauigkeit beibehalten.Dies ist besonders wichtig bei Smartphones, eingebetteten Systemen, Smart-Kameras, tragbaren Elektronikgeräten und anderen Edge-KI-Geräten, bei denen die Speicherkapazität und die Energieeffizienz begrenzt sind.
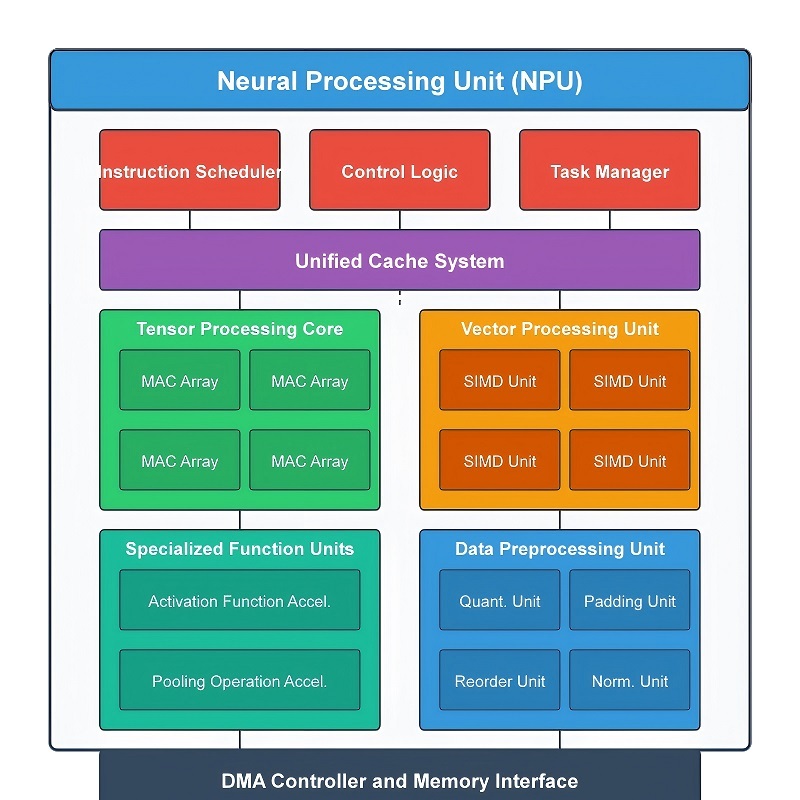
Wie diese Module zusammenarbeiten
Die Leistung einer NPU hängt nicht von einem einzelnen Hardwareblock ab.Seine Effizienz ergibt sich daraus, dass alle Verarbeitungsmodule als koordinierte Pipeline zusammenarbeiten.
Eine typische KI-Arbeitsbelastung beginnt mit umfangreichen mathematischen Berechnungen innerhalb der MAC-Einheiten.Zwischenergebnisse durchlaufen dann die Aktivierungsverarbeitung, um nichtlineares Verhalten in das neuronale Netzwerk einzuführen.Tensorbeschleunigungshardware organisiert und verarbeitet kontinuierlich mehrdimensionale Daten in der gesamten Pipeline, während räumliche Verarbeitungsmodule bild- und videobezogene Vorgänge verwalten.Gleichzeitig reduziert die Komprimierungshardware den Speicherübertragungsaufwand im Hintergrund.
Da diese Vorgänge gleichzeitig über dedizierte Hardwarepfade ausgeführt werden, kann die NPU große KI-Arbeitslasten mit hohem Durchsatz, geringerer Latenz und weitaus besserer Energieeffizienz als herkömmliche Prozessoren verarbeiten.
NPUs in Smartphones und mobiler KI
Moderne Smartphones erledigen jede Sekunde eine Vielzahl von Vorgängen.Ein Telefon kann fast sofort per Gesichtserkennung entsperrt, die Kamera geöffnet, Fotos verarbeitet, Sprache übersetzt und KI-gestützte Anwendungen ausgeführt werden.Um dieses Leistungsniveau in dünnen Mobilgeräten mit begrenzter Akkukapazität zu unterstützen, sind Smartphones auf hochintegrierte System-on-Chip-Architekturen (SoC) angewiesen.
Im SoC arbeiten mehrere Prozessoren zusammen und jeder Prozessor ist für eine andere Arbeitslast optimiert.Die CPU verwaltet die Systemsteuerung, Anwendungen und allgemeine Computeraufgaben.Die GPU übernimmt Grafik-Rendering, Spiele und visuelle Verarbeitung.Die NPU (Neural Processing Unit) konzentriert sich speziell auf KI-Berechnungen.
Anstatt Arbeitslasten neuronaler Netzwerke über die CPU oder GPU zu leiten, leiten Smartphones viele KI-Aufgaben an die NPU, wo die Hardware für eine schnelle parallele KI-Verarbeitung optimiert ist.Diese Trennung verbessert die Effizienz, da jeder Prozessor die Art der Arbeitslast bewältigt, für die er entwickelt wurde.Dadurch können Smartphones erweiterte KI-Operationen mit schnelleren Reaktionszeiten, geringerer Latenz und besserer Energieeffizienz durchführen.
Wie NPUs die Smartphone-KI veränderten
Bevor mobile NPUs verbreitet wurden, waren viele KI-Funktionen von Smartphones stark vom Cloud Computing abhängig.Aufgaben wie Spracherkennung, Sprachübersetzung, Bildverbesserung und intelligente Assistenten erforderten häufig das Hochladen von Daten auf Remote-Server zur Verarbeitung, bevor die Ergebnisse an das Gerät zurückgegeben wurden.Dies führte zu Verzögerungen, erhöhtem Netzwerkverkehr und Anlass zu Datenschutzbedenken.
Die Einführung dedizierter mobiler NPUs hat diesen Arbeitsablauf erheblich verändert.KI-Modelle könnten nun direkt auf dem Smartphone selbst ausgeführt werden, wodurch viele Vorgänge lokal in Echtzeit ausgeführt werden könnten, anstatt vollständig von externen Servern abhängig zu sein.
Dieser Wandel brachte mehrere große Vorteile mit sich:
• Geringere Latenz, da Daten keine ständige Cloud-Kommunikation mehr erfordern
• Schnellere KI-Reaktionszeiten im Echtzeitbetrieb
• Besserer Schutz der Privatsphäre, da sensible Daten auf dem Gerät verbleiben können
• Geringerer Stromverbrauch durch speziell für KI-Workloads optimierte Hardware
• Stabilere KI-Leistung auch bei schwachen oder nicht verfügbaren Internetverbindungen
Als mobile NPUs immer leistungsfähiger wurden, begannen Smartphones, erweiterte KI-Funktionen kontinuierlich im Hintergrund auszuführen, ohne dass es im täglichen Gebrauch zu merklichen Verzögerungen kam.
Wie Smartphones NPUs im realen Betrieb nutzen
KI-Fotografie und Bildverarbeitung
Eine der sichtbarsten Anwendungen mobiler NPUs ist die KI-Fotografie.Moderne Smartphone-Kameras verlassen sich nicht mehr nur auf Bildsensoren und herkömmliche Bildverarbeitungsalgorithmen.KI-Modelle analysieren nun kontinuierlich Bilddaten, während die Kamera in Betrieb ist.
Beim Öffnen der Kamera-App beginnt das Smartphone sofort damit, den eingehenden Bildstrom Bild für Bild zu verarbeiten.Die NPU analysiert Lichtverhältnisse, Objektgrenzen, Gesichtsdetails, Farben, Texturen und Bewegungsmuster in Echtzeit.Basierend auf dieser Analyse passt das System Belichtung, Weißabgleich, HDR-Einstellungen, Schärfe und Kontrast fast unmittelbar vor der Aufnahme des Bildes an.
Bei der Fotografie bei schlechten Lichtverhältnissen kombiniert die NPU mehrere Einzelbilder, um die Helligkeit zu verbessern und gleichzeitig visuelles Rauschen zu reduzieren.Bei der Porträtfotografie trennt der Prozessor Vordergrundmotive von Hintergrundbereichen und wendet Tiefeneffekte genauer an Kanten wie Haaren, Brillen und Kleidungskonturen an.
Die Szenenerkennung hängt auch stark von der NPU ab.Der Prozessor vergleicht Bildmuster mit trainierten KI-Modellen, um Umgebungen wie Lebensmittel, Landschaften, Haustiere, Dokumente, Sonnenuntergänge oder Nachtszenen zu identifizieren.Sobald die Kamera erkannt wurde, passt sie die Einstellungen automatisch an, um die Bildqualität zu optimieren.
Da diese Berechnungen direkt auf dem Smartphone erfolgen, fühlt sich die KI-Fotografie nahezu augenblicklich an, auch wenn im Hintergrund kontinuierlich große Mengen an neuronalen Netzwerkberechnungen stattfinden.
Spracherkennung und KI-Assistenten
Auch Sprachassistenten und sprachbezogene Funktionen sind stark auf die lokale KI-Beschleunigung angewiesen.Wenn ein Benutzer mit dem Smartphone spricht, erfasst das Mikrofon rohe Audiosignale, die gereinigt, getrennt und in erkennbare Sprachmuster umgewandelt werden müssen.
Die NPU verarbeitet den Audiostream kontinuierlich, indem sie Phoneme identifiziert, Hintergrundgeräusche filtert und Klangmuster mit Spracherkennungsmodellen abgleicht.Die lokale KI-Verarbeitung ermöglicht die nahezu sofortige Erkennung von Weckwörtern und gängigen Sprachbefehlen, ohne dass ständig Audioaufzeichnungen an Cloud-Server übertragen werden müssen.
Dies verbessert die Reaktionsfähigkeit für Aufgaben wie:
• Sprachbefehle
• Sprachtranskription in Echtzeit
• Sprachübersetzung
• Interaktion mit KI-Assistenten
• KI-Anrufverbesserung
• Rauschunterdrückung bei Videoanrufen
Da ein Großteil der Verarbeitung direkt auf dem Gerät erfolgt, bleibt die Sprachinteraktion auch unter instabilen Netzwerkbedingungen reibungsloser.
KI-Gaming und Echtzeit-Systemoptimierung
Auch moderne Smartphones nutzen NPUs zur Spieleoptimierung und intelligenten Systemverwaltung.Während des Spiels überwachen KI-Modelle den Frame-Rendering-Bedarf, das Arbeitslastverhalten, die thermischen Bedingungen, Berührungseingabemuster und den Batterieverbrauch in Echtzeit.
Das System kann die GPU-Arbeitslast dynamisch anpassen, die Leistungszuteilung optimieren, die Bildraten stabilisieren und Überhitzung bei langen Gaming-Sitzungen reduzieren.Einige Smartphones verwenden auch KI-Upscaling- und Bewegungsvorhersagetechniken, um die visuelle Darstellung zu verbessern und gleichzeitig den Stromverbrauch zu senken.
Außerhalb von Spielen hilft die NPU dabei, Hintergrundanwendungen, Batteriemanagement, vorausschauende Benutzerinteraktionen und Aufgabenplanung basierend auf Gerätenutzungsmustern zu optimieren.
Entwicklung mobiler NPUs
Die Entwicklung mobiler NPUs beschleunigte sich rasant, da die KI-Arbeitslasten von Smartphones immer fortschrittlicher und rechenintensiver wurden.
|
Zeitraum |
Mobile NPU-Entwicklung |
|
2017 – Frühe kommerzielle mobile NPUs |
Huawei stellte eines der ersten kommerziellen Smartphones vor
NPUs über den Kirin 970-Prozessor.Dies markierte einen großen Wandel in Richtung
groß angelegte On-Device-KI-Beschleunigung in Consumer-Smartphones.Statt
Sie verlassen sich bei KI-Aufgaben hauptsächlich auf CPUs und GPUs, mittlerweile auch auf Smartphones
dedizierte KI-Hardware direkt innerhalb der SoC-Architektur. |
|
2018 – Erweiterung der On-Device AI |
Apple hat die Neural Engine im A12 Bionic eingeführt
Chip, der die KI-Verarbeitung für die Gesichtserkennung verbessert, rechnerisch
Fotografie und intelligente mobile Funktionen.KI auf dem Gerät wurde zu einem wichtigen Thema
Schwerpunkt auf der Entwicklung von Flaggschiff-Smartphones. |
|
2019–2020 – Branchenweite KI-Integration |
Große Chiphersteller wie Qualcomm, Samsung und
MediaTek begann mit der Integration dedizierter KI-Beschleuniger in Flaggschiff-Mobilgeräte
Prozessoren.Die KI-Leistung wurde zu einem wichtigen Wettbewerbsfaktor
Smartphone-Hardware-Design. |
|
2021–2023 – KI-Verarbeitung wird zum zentralen Maßstab |
Smartphone-Hersteller verglichen zunehmend NPU
Leistung neben CPU- und GPU-Leistung.NPUs wurden zu einem zentralen Thema
Computerfotografie, Sprach-KI, Videoverbesserung, Batterieoptimierung,
und intelligente Systemfunktionen. |
|
2024–2025 – Große KI-Modelle laufen auf Smartphones |
Moderne mobile NPUs verfügen über genügend Rechenleistung
Unterstützen Sie größere KI-Modelle direkt auf Smartphones und Edge-Geräten.Mehr KI
Workloads könnten nun lokal ausgeführt werden, ohne stark von der Cloud abhängig zu sein
Infrastruktur und verbessert so sowohl die Reaktionsfähigkeit als auch den Datenschutz. |
Vergleich aktueller Mainstream-Mobil-NPUs
Moderne Flaggschiff-Smartphone-Prozessoren verfügen jetzt über hochentwickelte NPU-Architekturen, die für KI-Inferenz in Echtzeit, hohen Durchsatz und verbesserte Energieeffizienz optimiert sind.
|
Mobiler Prozessor |
NPU-Funktionen |
|
Apple A17 Pro |
Enthält eine 26-Kern-Neuronale Engine, die für schnelles Arbeiten ausgelegt ist
KI-Verarbeitung auf dem Gerät.Die Architektur verbessert KI-Fotografie und Sprache
Erkennung und intelligente Echtzeit-Systemfunktionen auf allen Apple-Geräten. |
|
Qualcomm Snapdragon 8 Gen 3 |
Verwendet einen aktualisierten Hexagon AI-Prozessor, der für optimiert ist
generative KI, Beschleunigung neuronaler Netzwerke, erweiterte Bildverarbeitung und
effiziente mobile KI-Workloads. |
|
MediaTek Dimensity 9300 |
Enthält eine APU (AI Processing Unit) der sechsten Generation mit
wesentliche Verbesserungen bei der KI-Inferenzgeschwindigkeit und der Echtzeit-KI-Verarbeitung
Fähigkeit für Smartphones und Edge-Geräte. |
|
Samsung Exynos 2400 |
Verfügt über eine mobile NPU der nächsten Generation, die auf Geschwindigkeit ausgelegt ist
KI-Verarbeitung auf dem Gerät für Computerfotografie, intelligentes System
Operationen und fortschrittliche mobile KI-Anwendungen. |
NPU vs. GPU vs. CPU: Hauptunterschiede in der KI-Verarbeitung
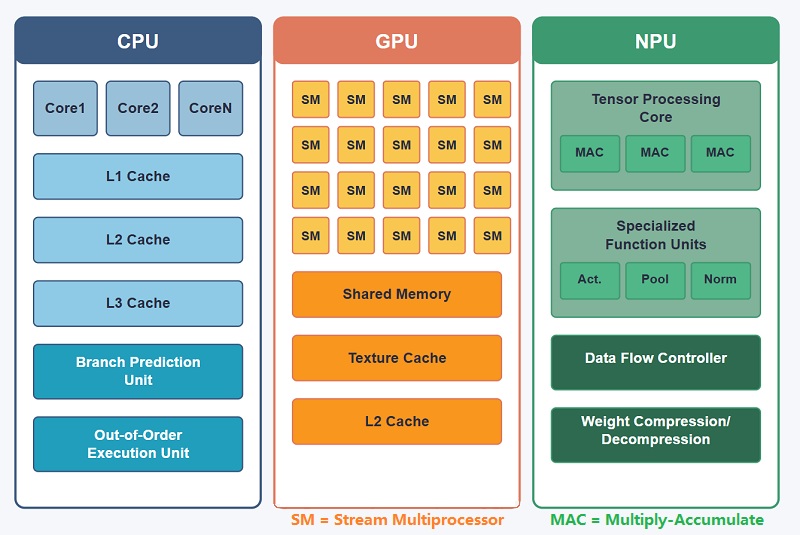
Sowohl GPUs als auch NPUs sind für die parallele Verarbeitung großer Datenmengen konzipiert, wurden jedoch für ganz unterschiedliche Zwecke gebaut.Eine GPU wurde ursprünglich für das Rendern von Grafiken entwickelt, während eine NPU speziell für die Berechnung neuronaler Netzwerke und KI-Inferenz entwickelt wurde. Aufgrund dieser unterschiedlichen Designziele bewältigen die beiden Prozessoren KI-Arbeitslasten auf sehr unterschiedliche Weise.GPUs können KI-Modelle effektiv ausführen, insbesondere in großen Trainingssystemen, sie weisen jedoch immer noch einen Großteil der Komplexität eines Grafikprozessors auf.NPUs vereinfachen viele dieser Vorgänge, indem sie sich fast ausschließlich auf KI-bezogene Berechnungen konzentrieren.
|
Funktion |
CPU
(Zentrale Verarbeitungseinheit) |
GPU
(Grafikverarbeitungseinheit) |
NPU
(Neuronale Verarbeitungseinheit) |
|
Hauptzweck |
Universell einsetzbar
Informatik und Systemsteuerung |
Parallel
Grafik und Hochleistungsrechnen |
KI-Inferenz und
Beschleunigung des neuronalen Netzwerks |
|
Primäre Arbeitsbelastung |
Betrieb
Systeme, Anwendungen, Multitasking |
Grafiken
Rendering, KI-Training, wissenschaftliches Rechnen |
KI-Verarbeitung,
Tensoroperationen, Deep-Learning-Inferenz |
|
Verarbeitungsstil |
Sequentielle
Verarbeitung |
Massive Parallele
Verarbeitung |
KI-optimiert
Parallelverarbeitung |
|
Kerndesign |
Nur wenige leistungsstarke und
flexible Kerne |
Tausende
parallele Ausführungskerne |
Spezialisierte KI
Beschleunigungseinheiten |
|
KI-Leistung |
Mäßig |
Hoch |
Sehr hoch für KI
Schlussfolgerung |
|
Matrix
Multiplikationsgeschwindigkeit |
Begrenzt |
Schnell |
Hoch optimiert |
|
Tensor
Verarbeitung |
Softwarebasiert |
Unterstützt
durch GPU-Beschleunigung |
Spezieller Tensor
Beschleunigungshardware |
|
Energieeffizienz |
Niedriger für KI
Arbeitsbelastungen |
Mäßig bis hoch
Stromverbrauch |
Hohe Leistung
effizient |
|
Wärmeerzeugung |
Mäßig |
Hoch unter Schwer
Arbeitsbelastungen |
Niedriger während AI
Schlussfolgerung |
|
Speicherbandbreite
Nutzung |
Mäßig |
Sehr hoch |
Optimiert und
reduziert |
|
Latenz in der KI
Aufgaben |
Höher |
Mäßig |
Sehr niedrig |
|
Echtzeit-KI
Fähigkeit |
Begrenzt |
Gut |
Ausgezeichnet |
|
Am besten für KI
Ausbildung |
Nicht ideal |
Ausgezeichnet |
Begrenzt im Vergleich
zu GPUs |
|
Am besten für KI
Schlussfolgerung |
Grundlegende Arbeitsbelastungen |
Leistungsstark
Schlussfolgerung |
Optimiert
Echtzeit-Inferenz |
|
Gewöhnlich
Anwendungen |
PCs, Server,
Betriebssysteme |
Gaming, KI
Training, Rendering, Simulationen |
Smartphones,
Edge-KI, Robotik, intelligente Kameras |
|
Abhängigkeit von
Cloud-KI |
Höher |
Mäßig |
Niedriger aufgrund
lokale KI-Beschleunigung |
|
Batterie
Effizienz in mobilen Geräten |
Niedriger |
Mäßig |
Hoch |
|
Typische Geräte |
Computer,
Laptops, Server |
Gaming-PCs, KI
Server, Workstations |
Smartphones, IoT
Geräte, Edge-KI-Hardware |
|
Kosten und
Komplexität |
Universell einsetzbar
Architektur |
Komplex
Hochleistungsarchitektur |
Spezialisiert
KI-fokussierte Architektur |
|
Hauptvorteil |
Flexibilität und
Systemverwaltung |
Großflächig
Parallelrechnung |
Schnell und
effiziente lokale KI-Verarbeitung |
Spezialisierte Verarbeitungseinheiten im modernen Computing
Abgesehen von NPU verwenden moderne Computersysteme viele verschiedene Prozessortypen, da keine einzelne Architektur jede Arbeitslast effizient bewältigen kann.Einige Prozessoren konzentrieren sich auf die Systemsteuerung, andere sind auf die Grafikwiedergabe spezialisiert, während andere für KI-Beschleunigung, Netzwerk, wissenschaftliches Rechnen oder eingebettete Steuerung optimiert sind.
In modernen Smartphones, Servern, Industriesystemen, Roboterplattformen, Fahrzeugen und Edge-KI-Geräten arbeiten oft mehrere Verarbeitungseinheiten gleichzeitig zusammen.Jeder Prozessor bewältigt die Art der Arbeitslast, für die er speziell entwickelt wurde, und verbessert so die Leistung, Energieeffizienz und Echtzeit-Reaktionsfähigkeit in modernen Computerumgebungen.
CPU: Zentraleinheit
Eine CPU (Central Processing Unit) ist der Hauptcontroller der meisten Computersysteme.Es verwaltet Betriebssysteme, Anwendungen, Speicherkoordination, Aufgabenplanung und Kommunikation zwischen Hardwarekomponenten.
CPUs sind äußerst flexibel und können viele verschiedene Arbeitslasten zuverlässig bewältigen, was sie in Computern, Smartphones, Servern und eingebetteten Systemen unverzichtbar macht.Im Vergleich zu spezialisierteren Prozessoren sind sie jedoch für umfangreiche parallele KI-Arbeitslasten weniger effizient.
GPU: Grafikverarbeitungseinheit
Eine GPU (Graphics Processing Unit) ist für die parallele Verarbeitung in großem Maßstab optimiert.Die Architektur enthält viele Ausführungskerne, die Tausende von Vorgängen gleichzeitig verarbeiten können.
GPUs wurden ursprünglich für das Rendern von Grafiken entwickelt, werden heute jedoch aufgrund ihrer starken Fähigkeit zur parallelen Berechnung häufig für KI-Training, wissenschaftliche Simulationen, Videoverarbeitung und Hochleistungsrechnen verwendet.
TPU: Tensor-Verarbeitungseinheit
Eine TPU (Tensor Processing Unit) ist für Tensor-basierte KI-Workloads und groß angelegte Deep-Learning-Beschleunigung optimiert.Diese Prozessoren sind hauptsächlich für Cloud-KI-Infrastrukturen und maschinelle Lernumgebungen in Rechenzentren konzipiert.
TPUs sind hochwirksam für:
• Deep-Learning-Schulung
• Große KI-Modelle
• Tensorberechnung
• Cloud-KI-Dienste
• KI-Beschleunigung mit hohem Durchsatz
FPGA: Rekonfigurierbare Hardwareverarbeitung
Ein FPGA (Field-Programmable Gate Array) nutzt programmierbare Logikblöcke, die nach der Herstellung für bestimmte Aufgaben konfiguriert werden können.Im Gegensatz zu festen Prozessorarchitekturen ermöglichen FPGAs die individuelle Anpassung der Hardwarefunktion selbst.
FPGAs werden häufig verwendet in:
• Kommunikationssysteme
• Automobilelektronik
• Industrielle Automatisierung
• Luft- und Raumfahrtsysteme
• Edge-Computing
• Medizinische Geräte
DPU: Datenverarbeitungseinheit
Eine DPU (Data Processing Unit) ist für datenzentrierte Arbeitslasten innerhalb von Cloud-Infrastrukturen und Netzwerksystemen optimiert.DPUs tragen dazu bei, die CPU-Auslastung zu reduzieren, indem sie die Datenbewegung, Speichervorgänge, Verschlüsselung und Netzwerkverkehrsverwaltung beschleunigen.
Diese Prozessoren werden häufig verwendet in:
• Rechenzentren
• Cloud-Computing
• Hochgeschwindigkeitsnetzwerk
• Speicherbeschleunigung
• Server-Infrastruktur
VPU: Vision Processing Unit
Eine VPU (Vision Processing Unit) ist auf Computer Vision und bildbasierte KI-Verarbeitung spezialisiert.VPUs beschleunigen Arbeitslasten wie Gesichtserkennung, Objekterkennung, Bewegungsverfolgung und Videoanalyse.
VPUs kommen häufig vor in:
• Intelligente Kameras
• Überwachungssysteme
• Robotik
• Autonome Fahrzeuge
• AR/VR-Systeme
• Edge-KI-Vision-Geräte
IPU: Intelligence Processing Unit
Eine IPU (Intelligence Processing Unit) ist für hochparallele KI- und maschinelle Lern-Workloads konzipiert.Die Architektur konzentriert sich auf die Verbesserung der Datenflusseffizienz während der Ausführung großer neuronaler Netzwerke.
IPUs werden verwendet für:
• Beschleunigung des maschinellen Lernens
• Mustererkennung
• KI-Inferenz
• Parallele Tensorverarbeitung
• Fortgeschrittene KI-Forschung
BPU: Brain Processing Unit
Eine BPU (Brain Processing Unit) ist für eingebettete KI- und Edge-Intelligence-Systeme optimiert.Diese Prozessoren konzentrieren sich auf schnelle lokale KI-Inferenz mit geringerem Stromverbrauch.
BPUs werden häufig verwendet in:
• Intelligente Sensorsysteme
• Robotik
• Edge-KI-Hardware
• Bewegungserkennungssysteme
• Autonome Plattformen
HPU: Holographische Verarbeitungseinheit
Eine HPU (Holographic Processing Unit) ist für holografische Computer-, Mixed-Reality- und räumliche Analysesysteme konzipiert.
HPUs unterstützen den Prozess:
• Umweltkartierung
• Bewegungsverfolgung
• Sensorfusion
• Räumliche Interaktion in Echtzeit
• AR/VR-Umgebungen
MPU und MCU: Embedded Control Processing
MPUs (Mikroprozessoreinheiten) und MCUs (Mikrocontrollereinheiten) werden häufig in eingebetteten Systemen und Elektronik mit geringem Stromverbrauch eingesetzt.
MPUs werden häufig in eingebetteten Computersystemen verwendet, die eine Steuerung auf Betriebssystemebene erfordern, während MCUs Prozessorkerne, Speicher und Eingabe-/Ausgabesteuerung in einem kompakten Chip für dedizierte Aufgaben mit geringem Stromverbrauch integrieren.
Diese Prozessoren sind häufig zu finden in:
• IoT-Geräte
• Industrielle Steuerungen
• Automobilelektronik
• Haushaltsgeräte
• Tragbare eingebettete Systeme
APU: Accelerated Processing Unit
Eine APU (Accelerated Processing Unit) vereint CPU- und GPU-Funktionalität in einem einzigen Prozessorpaket.Diese Integration verbessert die Energieeffizienz, reduziert die Hardwaregröße und ermöglicht es Computer- und Grafik-Workloads, Systemressourcen effizienter zu teilen.
APUs werden häufig verwendet in:
• Laptops
• Mini-PCs
• Gaming-Systeme der Einstiegsklasse
• Multimedia-Geräte
• Tragbare Computerplattformen
Warum moderne Systeme mehrere spezialisierte Prozessoren verwenden
Moderne Computersysteme basieren selten auf einer Einzelprozessorarchitektur.Stattdessen kombinieren Geräte mehrere spezialisierte Prozessoren miteinander, da unterschiedliche Arbeitslasten unterschiedliche Verarbeitungsmethoden erfordern.
Ein modernes System kann beispielsweise Folgendes verwenden:
• CPUs zur Systemsteuerung
• GPUs für Grafik und parallele Berechnungen
• NPUs für KI-Inferenz
• VPUs für Computer Vision
• DPUs für Netzwerk- und Datenbewegungen
• MCUs für eingebettete Steuerungsaufgaben
Durch die Verteilung von Arbeitslasten auf dedizierte Hardware erzielen moderne Systeme eine bessere Leistung, geringere Latenz, verbesserte Energieeffizienz und eine effektivere Echtzeitverarbeitung in KI-, Grafik-, Netzwerk- und eingebetteten Computerumgebungen.
Fazit
NPUs werden im modernen Computing immer wichtiger, da sie es ermöglichen, KI-Aufgaben lokal, schnell und effizient auszuführen, ohne stark von der Cloud-Verarbeitung abhängig zu sein.Ihre optimierte Architektur reduziert Latenz, Stromverbrauch, Speicherbewegung und Wärmeerzeugung und macht sie wertvoll für Smartphones, Robotik, Gesundheitsgeräte, industrielle Automatisierung, Smart Homes, autonome Systeme und Edge-KI-Plattformen.Da KI-Modelle immer größer und komplexer werden, werden zukünftige NPUs durch intelligentere Architekturen, Rechenleistung mit geringer Präzision, In-Memory-Verarbeitung, lokale Unterstützung großer Modelle, fortschrittliches Halbleiterdesign und stärkere KI-Sicherheitsfunktionen weiter verbessert.
Häufig gestellte Fragen [FAQ]
1. Warum sind NPUs für neuronale Netzwerk-Workloads effizienter als CPUs?
NPUs sind effizienter, da ihre Hardware speziell für KI-Berechnungen statt für allgemeine Verarbeitung ausgelegt ist.Eine CPU erledigt viele verschiedene Systemaufgaben nacheinander, während sich eine NPU hauptsächlich auf Tensoroperationen, Matrixmultiplikation, Faltung und parallele neuronale Netzwerkverarbeitung konzentriert.Dadurch können NPUs die KI-Inferenz schneller abschließen und dabei weniger Strom verbrauchen und weniger Wärme erzeugen.
2. Wie verbessert die Parallelverarbeitung die NPU-Leistung während der KI-Inferenz?
NPUs unterteilen KI-Arbeitslasten in viele kleinere Vorgänge, die gleichzeitig auf mehreren Recheneinheiten ausgeführt werden.Anstatt auf den Abschluss einer Anweisung zu warten, bevor eine andere Anweisung gestartet wird, werden große Mengen neuronaler Netzwerkdaten parallel durch den Prozessor geleitet.Dies verbessert den Durchsatz erheblich und reduziert die Latenz bei Arbeitslasten wie Bilderkennung, Sprachverarbeitung und Echtzeit-Objekterkennung.
3. Warum ist eine Berechnung mit geringer Präzision in modernen NPUs wichtig?
Viele KI-Modelle erfordern keine extrem hohe numerische Präzision, um genaue Ergebnisse zu liefern.NPUs verwenden Formate wie INT8 und FP16, um die Speichernutzung und den Rechenaufwand zu reduzieren.Durch die Verarbeitung mit geringerer Präzision können mehr Vorgänge in kürzerer Zeit abgeschlossen werden, während gleichzeitig die Energieeffizienz verbessert und eine starke KI-Inferenzleistung aufrechterhalten wird.
4. Wie reduzieren NPUs im Vergleich zu GPUs Engpässe bei der Speicherübertragung?
NPUs platzieren Speicher und Rechenhardware innerhalb der Prozessorarchitektur näher beieinander.Anstatt immer wieder große Mengen an Tensordaten zwischen externem Speicher und Verarbeitungskernen zu übertragen, bleiben viele Zwischenoperationen in der Nähe der Ausführungseinheiten.Dies verkürzt die Datenwege, reduziert die Bandbreitennutzung, verringert die Latenz und verbessert die Gesamtenergieeffizienz.
5. Warum werden NPUs in Smartphones und Edge-KI-Geräten immer nützlicher?
Moderne Geräte erfordern eine schnelle lokale KI-Verarbeitung mit geringem Stromverbrauch und minimaler Latenz.NPUs ermöglichen es Smartphones und Edge-Systemen, KI-Aufgaben wie Gesichtserkennung, KI-Fotografie, Sprachinteraktion und Objekterkennung direkt auf dem Gerät auszuführen, ohne stark von Cloud-Servern abhängig zu sein.Dies verbessert die Reaktionsfähigkeit, den Datenschutz und die Akkueffizienz.
6. Wie tragen MAC-Einheiten zur NPU-Beschleunigung bei?
Multiply-Accumulate (MAC)-Einheiten verarbeiten die wiederholten Multiplikations- und Additionsoperationen, die in neuronalen Netzwerken verwendet werden.Moderne NPUs enthalten Hunderte oder Tausende gleichzeitig arbeitende MAC-Einheiten, wodurch große KI-Arbeitslasten viel schneller verarbeitet werden können als auf herkömmlichen sequentiellen Prozessoren.
7. Warum nutzen moderne KI-Systeme sowohl GPUs als auch NPUs, anstatt sich auf einen Prozessortyp zu verlassen?
GPUs und NPUs sind für unterschiedliche Arbeitslasten optimiert.GPUs zeichnen sich durch groß angelegtes KI-Training, Grafik-Rendering und leistungsstarke parallele Berechnungen aus, während NPUs für KI-Inferenz mit geringem Stromverbrauch und lokale Echtzeitverarbeitung optimiert sind.Durch die gemeinsame Verwendung beider Prozessoren können Systeme Flexibilität, Leistung und Energieeffizienz in Einklang bringen.
8. Wie verbessern NPUs die Echtzeit-KI-Verarbeitung in Robotik und autonomen Systemen?
Robotik und autonome Systeme verarbeiten kontinuierlich Kameraeingaben, Umgebungskartierungen, Sensordaten und Bewegungsanalysen.NPUs beschleunigen diese Arbeitslasten lokal mit geringer Latenz, sodass Systeme bei der Navigation, Hinderniserkennung, Fußgängererkennung und Entscheidungsfindung in Echtzeit schnell reagieren können.
9. Warum wird die On-Device-KI für die zukünftige NPU-Entwicklung immer wichtiger?
KI auf dem Gerät reduziert die Abhängigkeit vom Cloud Computing, indem sie die direkte Ausführung von KI-Modellen auf lokaler Hardware ermöglicht.Dies verbessert den Datenschutz, verringert die Nutzung der Netzwerkbandbreite und ermöglicht schnellere Reaktionen in Echtzeit.Von künftigen NPUs wird erwartet, dass sie größere lokale KI-Modelle, multimodale KI-Verarbeitung und fortschrittliche generative KI-Workloads direkt in Verbraucher- und Industriegeräten unterstützen.
10. Wie könnten zukünftige NPU-Architekturen die Effizienz der KI-Hardware verändern?
Zukünftige NPUs werden wahrscheinlich eine intelligentere Workload-Zuteilung, Sparse Computing, In-Memory-Verarbeitung, Chiplet-Architekturen und adaptive Präzisionssteuerung nutzen, um die Effizienz zu verbessern.Diese Technologien zielen darauf ab, unnötige Berechnungen zu reduzieren, den Stromverbrauch zu senken und den Durchsatz zu erhöhen, während sie gleichzeitig größere und fortschrittlichere KI-Modelle für Edge-Geräte, Robotik, Industriesysteme und intelligente Unterhaltungselektronik unterstützen.
Verwandter Blog
-
Wie viele Nullen in einer Million, Milliarden, Billionen?
![Wie viele Nullen in einer Million, Milliarden, Billionen?]()
2024/07/29
Millionen repräsentieren 106, eine leicht griffbare Figur im Vergleich zu alltäglichen Gegenständen oder jährlichen Gehältern. Milliarden, entspr... -
IRLZ44N MOSFET -Datenblatt, Schaltung, Äquivalent, Pinout
![IRLZ44N MOSFET -Datenblatt, Schaltung, Äquivalent, Pinout]()
2024/08/28
Der IRLZ44N ist ein weit verbreiteter N-Kanal-Power-MOSFET.Es ist bekannt für seine hervorragenden Schaltkapazitäten und eignet sich sehr für zahlr... -
Batteriestemperatur zu niedrig, das Laden gestoppt.Wie repariere ich es?
![Batteriestemperatur zu niedrig, das Laden gestoppt.Wie repariere ich es?]()
2024/10/6
Das Ladeproblemen von Mobiltelefonen sind häufig, können jedoch effektiv verwaltet werden.Die Temperatur spielt eine große Rolle bei der Batterieff... -
BC547 Transistor umfassender Leitfaden
![BC547 Transistor umfassender Leitfaden]()
2024/07/4
Der BC547 -Transistor wird üblicherweise in einer Vielzahl elektronischer Anwendungen verwendet, die von grundlegenden Signalverstärkern bis hin zu ... -
Umfassende Anleitung zum SCR (Siliziumgesteuerte Gleichrichter)
![Umfassende Anleitung zum SCR (Siliziumgesteuerte Gleichrichter)]()
2024/04/22
Siliziumkontrollierte Gleichrichter (SCR) oder Thyristoren spielen aufgrund ihrer Leistung und Zuverlässigkeit eine entscheidende Rolle in der Energi... -
LR621, SR621SW, 364, AG1 -Batterieäquivalente und Ersatz
![LR621, SR621SW, 364, AG1 -Batterieäquivalente und Ersatz]()
2024/07/15
Die Batterien von LR621- und SR621SW -Tasten sind in kompakten elektronischen Geräten wie Uhren, kleinen Spielzeugen, Taschenrechnern und Fernschlüs... -
Grundlagen von Op-Ampere-Schaltungen
![Grundlagen von Op-Ampere-Schaltungen]()
2023/12/28
In der komplizierten Welt der Elektronik führt uns eine Reise in ihre Geheimnisse ausnahmslos zu einem Kaleidoskop aus exquisiten und komplexen Schal... -
Vergleich der Unterschiede und Anwendungen von NMOs und PMOS
![Vergleich der Unterschiede und Anwendungen von NMOs und PMOS]()
2024/11/15
Das Verständnis der Unterschiede zwischen NMOS- und PMOS -Transistoren ist wichtig für die Gestaltung effizienter Schaltkreise.NMOs (N-Type-Metallox... -
Ein vollständiger Leitfaden für Multiplexer und ihre Rolle in digitalen Systemen
![Ein vollständiger Leitfaden für Multiplexer und ihre Rolle in digitalen Systemen]()
2025/09/20
Multiplexer sind Komponenten in digitalen Systemen, mit denen mehrere Eingangssignale unter Verwendung binärer Logik- und Kontrollsignale in eine ein... -
Was bedeuten STD, AGM und Gel auf einem Batterieladegerät?
![Was bedeuten STD, AGM und Gel auf einem Batterieladegerät?]()
2024/07/10
Herkömmliche Ladegeräte für Blei-Säure-Batterien sind für ihre Einfachheit und Zuverlässigkeit bekannt.Sie dienen ihren Zweck seit Jahren effekt...









Heiße Teile
- TPS71733DCKR
- ATSAMD21J18A-MUT
- 12065A1R5BAT2A
- NJM2504RB1-TE1
- UCS81003AMR-C1A
- EMIF03-S1M01F1U8
- R5F100GEAFB#V0
- LPC1114FBD48/303
- TAP685M016SRS
- T491S475M010AT
- AT17LV256-10PI
- ATA2741M-TCQY
- 2SK1794
- GRM1886S1H7R9DZ01D
- T266SAB/Q
- DMC2700UDM-7
- TSC2046IPWR
- UPD65951S1-E32-F6
- BCM3451KMLG
- CC2564MODNCMOER
- XC2S200E-6FT256I
- EDB4432BBPA-1D-F-D
- T491D477K006AT
- S71PL032J40BAW0K0
- ICS952508BGLF
- C8051F352-GQR
- 08055A101GAT4A
- MC14584BFL1
- 06035C122JAT4A
- LTC1645IS8
- STM32L051T8Y6DTR
- AT9056-A3
- AD7574SQ
- C1608C0G1H750J
- AK4129VQ
- LTC6101HVACMS8#PBF
- MCF52223CAF80
- EPC2TI32N
- RC1206FR-07133KL
- 08053C562MAT2A
- BTS737S2
- T491B106K010AT4539
- K4S1616220-TC10
- QG82945GZ
- S29AL008D90BAI02
- BA7149F-T1
- PMEW2520
- S05071D1PZPRG4
- EM2280P01QI
- MB90F055PMC1-G-SNE1