- Deutsch
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Wie IoT-Geräte funktionieren: Architektur, Komponenten und Leistungsfaktoren
Katalog
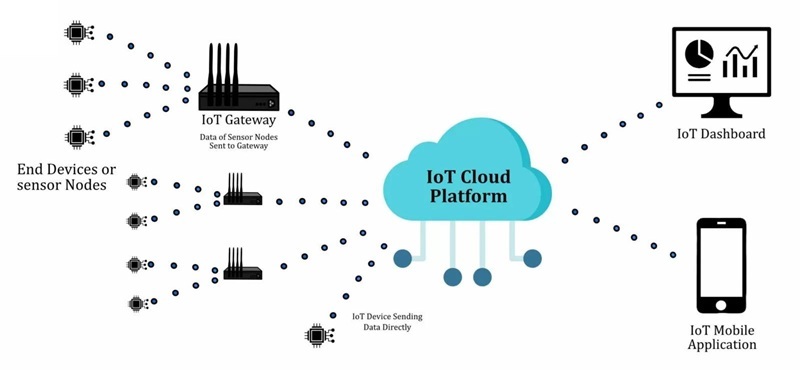
Wie ein IoT-Gerät funktioniert
Ein IoT-Produkt ist einfacher zu verstehen, wenn es als geschlossener, messbarer Kreislauf betrachtet wird: Es beobachtet die physische Welt, wandelt das, was es beobachtet hat, in Daten um, die die Elektronik verarbeiten kann, überträgt diese Daten an einen Ort, an dem sie interpretiert werden können, und löst dann eine Reaktion aus. Viele Teams beginnen mit der Verfolgung von „Konnektivität“, und das ist verständlich, Demos sehen großartig aus, wenn das Dashboard in Echtzeit aktualisiert wird, aber im Feld wird das Gerät daran gemessen, ob es am Tag 3, am Tag 30 und am Tag 300 gleich verhält.
Der Kreislauf muss alltägliche Einschränkungen überstehen, die sich oft zur ungünstigsten Zeit zeigen: begrenzte Energie, unpredictable Latenz, Interferenzen, Kostenobergrenzen und sich entwickelnde Sicherheitsanforderungen. Wenn der Kreislauf unter Berücksichtigung dieser Einschränkungen entworfen wird, wirken die Netzwerk- und Cloud-Schichten wie eine saubere Erweiterung des Produkts, anstatt eine Quelle für Überraschungen und fragilen Grenzfälle zu sein.
Erfassen: Ein physikalisches Signal in ein elektrisches umwandeln
Am Edge wandelt ein Sensor eine reale Variable in eine elektrische Darstellung um, die das Gerät messen kann. Die Variable kann umweltbedingt, mechanisch oder elektrisch sein, und die Aufgabe des Sensors besteht darin, ein Signal zu erzeugen, das bei Temperaturänderungen, Vibrationen und Installationsvariabilität interpretierbar bleibt.
Häufig gemessene reale Variablen:
• Temperatur
• Vibration
• Druck
• Licht
• Bewegung
• Strom
• Gaskonzentration
Die Ausgabe des Sensors landet typischerweise in einer von zwei Kategorien, und die Wahl beeinflusst alles, was darunter liegt (Frontend-Design, Abtastung und Rauschunterdrückung).
Häufige Sensorausgabetypen:
• Analog: eine kontinuierlich variierende Spannung oder einen Strom
• Digital: paketisierte Messwerte über I²C/SPI/UART
Außerhalb von Laborbedingungen hängt die Messgenauigkeit von mehr ab als nur vom Sensor selbst. Installationsfaktoren wie Platzierung, Montagekraft, Luftstrom, nahe Wärmequellen, Kabelverlegung und mechanische Kopplung können die Ergebnisse erheblich beeinflussen.
Messfehler werden oft durch Installationsprobleme und nicht durch Sensorfehler verursacht. Flexible Montagesflächen oder resonante Strukturen können Daten verzerren und irreführende Messwerte erzeugen. Die Behandlung von Montage und mechanischem Design als Teil des Messsystems hilft, die Fehlersuche zu verkürzen und die Messzuverlässigkeit zu verbessern.
Bedingen: Analoges Front-End (AFE) und Signalhygiene
Viele Geräte leiten rohe Sensorausgaben über ein analoges Frontend (AFE) weiter, bevor sie digitalisiert werden. Diese Phase formt leise, ob der Rest des Systems mit einem stabilen, vertrauenswürdigen Signal oder mit etwas arbeitet, das nur unter kontrollierten Bedingungen funktioniert.
Typische AFE-Funktionen:
• Bias- und Referenzerzeugung, um die Signale im gültigen Eingangsbereich des ADC zu halten
• Verstärkung (Instrumentierungsverstärker, Verstärkungsstufen), um kleine Signale messbar zu machen
• Filterung (Tiefpass, Anti-Aliasing-Filter) zur Reduzierung von Rauschen und zur Begrenzung irreführender hochfrequenter Inhalte
• Schutz (ESD-Strukturen, Überspannungsschutz, Eingangs-Klemmen) zur Überlebenssicherung bei Verdrahtungsfehlern und Handhabung
Reale Betriebsumgebungen führen häufig Rauschquellen wie Motoren, lange Kabel, Schaltnetzteile und nahe Radios ein. Diese Effekte können Messfehler verursachen, die zufällig erscheinen, bis die Quelle identifiziert ist.
Gute Erdung, ordnungsgemäße Abschirmung und grundlegende Anti-Aliasing-Filterung verbessern oft die Signalqualität effektiver, als sich nur auf komplexe Softwarefilterung zu verlassen. Die Bekämpfung von Rauschen an der Quelle führt in der Regel zu zuverlässigeren Messungen und Systemleistungen.
Konvertieren: ADC-Abtastung mit absichtlichen Kompromissen
Wenn das Signal analog ist, wandelt ein ADC es in digitale Proben um. Die Umwandlung selbst ist einfach; was Erfahrung erfordert, ist das Auswählen von Abtastparametern, die sich unter den realen Batterie- und Netzwerkgrenzen gut verhalten.
Zwei Abtastwahlmöglichkeiten, die das nachgelagerte Verhalten prägen:
• Abtastrate: schnell genug, um das Phänomen zu erfassen, aber nicht so schnell, dass es Leistung verbraucht und unnötige Daten produziert
• Auflösung: fein genug, um signifikante Veränderungen zu erkennen, ohne Rauschen und Drift in falsche Präzision zu verwandeln
Sampling funktioniert am besten, wenn es als systemweite Entscheidung behandelt wird, anstatt als isolierte Spezifikation. Oversampling kann stillschweigend mehr Funkaktivität erzwingen (und Funkzeit ist oft das erste, was den Akku entleert). Undersampling kann kurzfristige, operationell bedeutende Ereignisse, Druckspitzen, Aufprälle und kurze Störungen, die sich die Benutzer merken, weil es der Moment war, in dem etwas schiefging, verpassen.
Berechnen: Mikrocontrollerverarbeitung, Timing und Edge-Logik
Ein Mikrocontroller (MCU) liest typischerweise Sensordaten nach einem disziplinierten Zeitplan unter Verwendung von Timern, Interrupts und DMA, sodass das Timing des Geräts konsistent bleibt, selbst wenn die Firmware wächst. Konsistentes Timing ist eines dieser Details, das langweilig erscheint, bis zu dem Tag, an dem Sie ein Feldproblem debuggen und feststellen, dass das „Signal“ tatsächlich eine Zeitplan-Flatterigkeit war.
Häufige Verarbeitungstasks auf der MCU-Seite:
• Digitale Filterung (Gleitender Durchschnitt, Median, IIR) zur Reduzierung von Jitter und Ausreißern
• Kalibrierung und Kompensation (Offset-Korrektur, Temperaturkompensation, Linearisation)
• Regelbewertung (Schwellenwerte, Hysterese, Entprellen) zur Vermeidung instabiler Umschaltungen
• Leichte Edge-Analytik (Merkmalsextraktion, Anomalie-Bewertung, Kompression) zur Reduzierung von Bandbreite und Cloud-Computing
Ein nützlicher Designansatz besteht darin, Messdaten von Entscheidungslogik zu trennen. Sensorablesungen können aufgrund normaler physikalischer Bedingungen schwanken, während das stabile Systemverhalten durch Hysterese, Zeitfenster und zustandsmaschinenbasierte Kontrolle aufrechterhalten werden kann. Diese Trennung hilft, Fehlalarme zu reduzieren, die Systemstabilität zu verbessern und falsche Fehlermeldungen zu verhindern, wenn vorübergehende Messvariationen auftreten.
Nicht jede Entscheidung profitiert davon, auf die Cloud zu warten. Einige Aktionen sind zeitkritisch oder auf Schadenvermeidung ausgerichtet, und sie von dem Gerät zu verschieben, neigt dazu, unangenehme Fehlerzustände zu erzeugen, wenn das Netzwerk langsam oder nicht vorhanden ist.
Beispiele, die häufig lokal behandelt werden:
• Überstromabschaltung; Überhitzungsschutz; Motorstillstandserkennung
Die Cloud glänzt oft, wenn die Aufgabe von einem breiteren Kontext oder längeren Zeitrahmen profitiert.
Entscheidungsarten auf der Cloud-Seite:
• Langfristige Trendanalyse und vorausschauende Wartung
• Gerätekorrelationen übergreifend
• Modellupdates und fleetweite Richtlinienänderungen
Eine praktische Regel, auf die sich Teams oft einigen, ist einfach: Wenn ein verzögerter Befehl plausibel zu Schäden führen könnte, sollte sich das Gerät zuerst selbst schützen und anschließend berichten. Dieser Ansatz wirkt oft auf eine gute Art konservativ, besonders wenn man der ist, der im Falle eines Netzwerkausfalls in Bereitschaft bleibt.
Kommunizieren: Funk-/Verdrahtete Verbindungen und Anwendungsprotokolle
Die Kommunikationsschicht überträgt Telemetrie zu einem Telefon, Gateway oder Cloud-Endpunkt. Die Auswahl einer Verbindungstechnologie hängt weniger davon ab, was im Trend liegt, sondern vielmehr davon, was zur physikalischen Umgebung, dem Bereitstellungsmodell und dem Leistungsbudget passt.
Häufige Konnektivitätsoptionen:
• Wi‑Fi; BLE; Zigbee/Thread; Mobilfunk (LTE-M/NB-IoT); Ethernet
Über der Verbindungsschicht verwenden Geräte Anwendungsprotokolle, um Nachrichten zu strukturieren und zu übermitteln. Das richtige Protokoll hängt oft davon ab, ob das Produkt Streaming-Telemetrie, Konfigurations-Workflows oder Kompatibilität mit vorhandener Unternehmensinfrastruktur benötigt.
Häufige Anwendungsprotokolle:
• MQTT
• HTTP
Echte Einsätze bieten selten eine stabile Konnektivität. Zugangspunkte rebooten, Gateways verschwinden, die Mobilfunkabdeckung variiert und Störungen kommen und gehen. Geräte wirken viel verlässlicher, wenn sie Daten zwischenspeichern können, mit Bedacht erneut versuchen (nicht auf eine Weise, die das Netzwerk DDOS-t), und ein klares Verhalten beim zuletzt bekannten Zustand beibehalten, sodass das System verständlich bleibt, wenn die Verbindungen unvollkommen sind.
Telemetrie ist typischerweise mit TLS zum Schutz der Vertraulichkeit und Integrität gesichert. In vielen Produkten ist der erste Sicherheitsgewinn einfach, die Verschlüsselung überall zu aktivieren, aber dauerhafte Sicherheit geht weiter, indem Identität und Updates über die gesamte Lebensdauer des Geräts verwaltet werden.
Häufige Sicherheitsbausteine:
• Einzigartige Geräteidentitäten und zertifikatsbasierte Authentifizierung
• Sichere Schlüsselverwaltung (sichere Elemente oder MCU-Vertrauenszonen)
• Signierte Firmware und sicherer Boot, um die Wahrscheinlichkeit einer unbefugten Codeausführung zu reduzieren
Es gibt ein Muster, das erfahrene Teams erkennen (oft nachdem sie es auf die harte Tour gelernt haben): Sicherheitsarbeit ist viel weniger schmerzhaft, wenn Identität, Schlüsselmanagement und Update-Pfade frühzeitig geplant werden. Wenn diese Grundlagen von Anfang an geplant sind, bleibt das Gerät in der Regel über Jahre hinweg nutzbar, nicht nur bis zum ersten größeren Feldupdate.
Cloud und Daten
In der Cloud (oder auf einer lokalen Plattform) werden Daten gespeichert, oft in Zeitreihensystemen, dann aggregiert und analysiert. Die Cloud ist der Ort, an dem rohe Telemetrie in Ausgaben umgewandelt werden kann, auf die jemand tatsächlich reagieren wird, egal ob diese Person ein Benutzer, ein Operator oder eine automatisierte Richtlinien-Engine ist.
Häufige Cloud-Ausgaben:
• Warnungen (Schwellenwertüberschreitungen, Fehlererkennung)
• Vorhersagen (verbleibende nützliche Lebensdauer, Drift-Erkennung)
• Dashboards (KPIs, Trends, Gesundheitszustand der Flotte/des Geräts)
• Steuerbefehle (Sollwerte, Zeitpläne, Aktionen aktivieren/deaktivieren)
Der Wert der Cloud lässt sich am einfachsten erfassen, wenn Teams im Voraus entscheiden, welche Entscheidungen die Daten unterstützen sollen. Ohne diese Disziplin hat Telemetrie die Tendenz, teurer Hintergrundlärm zu werden, der zuverlässig erfasst, pflichtbewusst gespeichert und dann selten mit Vertrauen genutzt wird.
Aktuieren: Befehle sicher und wiederholbar ausführen
Befehle, die an das Gerät zurückgesendet werden, steuern Aktoren, und dieser Teil des Kreislaufs ist der, in dem die Hardware-Realität laut wird. Die Aktuierung erfordert Treiber-Schaltungen, die auf die Last abgestimmt sind, und profitiert von Schutzvorrichtungen, die Fehler vorhersehbar machen, anstatt chaotisch.
Häufige Aktoren:
• Motoren
• Ventile
• Relais
• Heizungen
• LEDs
• Lautsprecher
Häufige Treiber- und Schutzelemente:
• MOSFETs; Relais; H-Brücken; Triacs (abhängig von den Lastmerkmalen)
• Flyback-Dioden und Snubber (für induktive Lasten)
• Strommessung und thermische Schutzvorrichtungen
• Zustandsüberprüfung, wenn verfügbar (Endschalter, Positionsfeedback, elektrische Signaturen)
Eine Denkweise über Zuverlässigkeit, die sich oft auszahlt, besteht darin anzunehmen, dass die Aktuierung der Punkt ist, an dem sich das Risiko konzentriert. Sensoren fallen oft still und leise aus; Aktoren können auf Weise ausfallen, die Benutzer sofort bemerken. Einfache Schutzmaßnahmen, Zeitüberschreitungen, Verriegelungen und Plausibilitätsprüfungen verhindern häufig kaskadierende Probleme und vermitteln ein vertrauenswürdigeres Gefühl in unweigerlichen seltsamen Randfällen.
Der Kreislauf wiederholt sich
Dieser Sinn; der Zyklus von Berechnen, Kommunizieren, Aktuieren wiederholt sich kontinuierlich. Lokal kann er in Millisekunden ablaufen; eine Cloud-Latenz kann je nach Netzwerk- und Backendlast Sekunden in Anspruch nehmen. Gute Produkte behandeln Timing und Energie als Entwurfsparameter, die jede andere Entscheidung prägen, anstatt sie als nachträgliche Überlegungen zu betrachten, die am Ende optimiert werden.
Häufige systemweite Strategien:
• Verwenden Sie Edge-Processing, um unnötige Übertragungen zu reduzieren
• Bündeln und Komprimieren von Telemetrie, wenn die Latenztoleranz dies zulässt
• Aggressiv schlafen und vorhersehbar in batteriebetriebenen Geräten aufwachen
• „Mindestlebensfähiges Verhalten“ aufrechterhalten, auch wenn die Cloud nicht erreicht werden kann
Ein langlebiges IoT-Gerät wird nicht durch eine einzige Komponente definiert. Es wird durch die Ruhe definiert, mit der der gesamte Kreislauf funktioniert, wenn die Realität vom Plan abweicht: laute Signale, intermittierende Netzwerke, alternde Hardware und unberechenbares Benutzerverhalten. Mit diesen Bedingungen im Hinterkopf zu gestalten, ist oft der Unterschied zwischen einer einmal funktionierenden Demo und einem Produkt, das Jahr für Jahr seine Gelassenheit bewahrt.
Elektronische Komponenten zur Leistung von IoT-Geräten
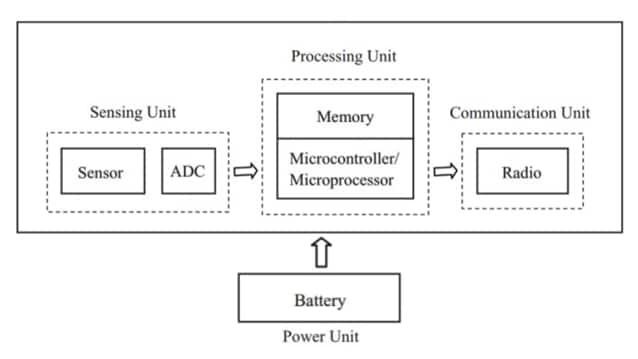
IoT-Hardware fühlt sich nur dann zuverlässig an, wenn Sensor-Eingänge, Berechnung, Speicherung, Energieversorgung und Konnektivität als ein kontinuierlicher Signal- und Energiepfad gestaltet sind.
Ein Sensorabstand bleibt selten sinnvoll, wenn die Referenzspannung schwankt, wenn die Uhr unregelmäßig läuft oder wenn der Datenpfad gelegentlich unter Last Bytes verliert. Eine Funkverbindung bleibt selten nutzbar, wenn die Stromversorgung während der Übertragungsimpulse nachlässt, wenn der Oszillator Geräusche macht oder wenn die Handhabung von Anmeldeinformationen über Resets hinweg inkonsistent ist.
Viele Teams lernen, dass die Zuverlässigkeit oft mehr durch das Verengen der Block-zu-Block-Grenzen verbessert wird als durch das Hinzufügen eines weiteren Merkmals: vorhersehbare Spannungen, begrenzte Timing, kontrollierte Geräuschkopplung und ein Fehlverhalten, das verständlich ist, wenn etwas kaputtgeht.
Das Designziel sind nicht "perfekte Teile", sondern Schnittstellen, die auf einem Entwicklerplatz, in Pilotanwendungen und Monate später im Feld gleich funktionieren.
Sensor
Sensoren wandeln reale Bedingungen in elektrische Signale um, aber das tägliche Produktverhalten wird von Details geprägt, die klein erscheinen können, bis Felddaten sie unangenehm groß erscheinen lassen.
Geräusche, Drift, Montage, Luftstrom, Kondensation und Kabelrouting haben alle die Eigenart, ein sauberes Laborplot in unordentliche Verteilungen zu verwandeln, in denen die Firmware überleben muss.
Reichweite und Auflösung müssen zur zu treffenden Entscheidung passen, nicht zu den Hauptspezifikationen. Übermäßig empfindliche Konfigurationen verstärken oft Geräusche und Drift, was dazu tendiert, falsch-positive Ergebnisse zu erhöhen und gleichzeitig die Rechen- und Funkzeit leise zu erhöhen. Eine möglichst enge Reichweite kann während der Designüberprüfungen vertretbar erscheinen, dennoch begünstigt das Verhalten im Feld oft eine etwas breitere Reichweite, die gleichmäßigere, besser interpretierbare Messungen liefert. Wenn ein nachgelagertes Modell oder Schwellenwert diese Daten ohnehin glätten wird, kann es zunächst befriedigend erscheinen, die Rohempfindlichkeit zu weit zu treiben, und dann frustrierend werden, wenn Support-Anfragen eintreffen.
Drift, Alterung und Exposition bestimmen, ob Messungen nach Monaten oder Jahren glaubwürdig bleiben.
Kalibrierung funktioniert in der Regel besser, wenn sie als Routine über den Lebenszyklus hinweg behandelt wird, anstatt als einzelnes Fabrikritual, bei dem jeder hofft, dass es für immer hält.
• Werkstattkalibrierung mit gespeicherten Koeffizienten.
• Vor-Ort-Rekalibrierungs-Trigger (geplante, ereignisbasierte oder technikerunterstützte).
• Selbstprüfroutinen, die Ausreißer, Clipping und Sättigung kennzeichnen.
Teams, die auf wartungsfähige Produkte abzielen, legen oft bescheidenen Flash- und Rechenplatz für Kalibrierungs-Metadaten, Rückverfolgbarkeit und Plausibilitätsprüfungen beiseite, da dies günstiger ist, als inkonsistente Messwerte nach der Bereitstellung zu erklären.
Die Auswahl der Abtastrate wird in der Regel zu einer Verhandlung zwischen Physik, Batterie und Nützlichkeit der Daten. Zu langsames Abtasten birgt das Risiko von Aliasing und verpassten Ereignissen, die schwer zu diagnostizieren sein können, da die Daten dennoch plausibel aussehen. Zu schnelles Abtasten erhöht den Stromverbrauch und das Datenvolumen und kann den Eindruck besserer Einsicht erwecken, ohne die Entscheidungen materiell zu verbessern.
Ein Muster, das sich gut hält, besteht darin, das Phänomen mit ausreichend Spielraum zu erfassen, früh zu filtern (analog, wenn es wirklich hilft, digital, wenn es ausreichend ist) und für die Berichterstattung zu unterabtasten.
Dies führt oft zu besseren Ergebnisse bezüglich der Batterie als aggressives Abtasten und die Hoffnung, dass Cloud-Analysen später kompensieren.
Ob ein externer ADC gerechtfertigt ist, hängt normalerweise von der Auflösung, dem Eingangswiderstand, der Referenzstabilität und der Geräusch-Toleranz ab. Integrierte ADCs in MCUs schneiden oft gut bei der Mittelauflösungs-Sensorik ab, während präzise Signale eine nachlässige Anordnung und Referenzentscheidungen bestraften.
• Auswahl einer rauscharmen Referenz und Routing der Referenz.
• Erdungsstrategie, Schutzleitungen und Rückwegkontrolle.
• Abschirmung und absichtliches Kabelrouting in der Nähe von Steckverbindern.
• ESD-Schutz an den Stellen, wo er tatsächlich den transienten Zustand abfängt.
Kleine PCB-Änderungen können messbar das Jitter reduzieren und die Wiederholgenauigkeit verbessern, insbesondere bei Hochimpedanzquellen oder niederpegeligen analogen Signalen, wo "fast in Ordnung" in den Produktionsdaten sichtbar instabil wird.
Mikrocontroller (MCU)
Der MCU fungiert als das betriebliche Zentrum: er liest Sensoren über GPIO, I²C, SPI und UART; bedingt Signale; führt Inferenz dort aus, wo es anwendbar ist; verwaltet Strommodi; und steuert Ausgänge.
Wenn das Verhalten des MCUs vorhersehbar ist, fühlt sich das gesamte Gerät ruhig an; wenn nicht, erscheinen Ausfälle oft zufällig, auch wenn die Ursache deterministisch ist.
Stabile Firmware stammt typischerweise aus expliziten Zustandsmaschinen und Timing, das klare Grenzen hat. Ereignisgesteuerte Designs, die Interrupts, DMA und Timer verwenden, übertreffen in der Regel Polling-Schleifen in Bezug auf Reaktivität und Energie, insbesondere in Geräten, die oft in den Energiesparmodus wechseln.
Wenn Teams von zufälligen Einfrierungen berichten, ist der Übeltäter häufig einer von wenigen Wiederholungstätern: unbegrenzte Arbeit innerhalb eines Interrupts, Deadlock im Shared-Bus, Prioritätsinversion oder Speicherfragmentierung, die unter langen Laufzeiten nie auf die Probe gestellt wurde.
Planung für RAM und Flash funktioniert besser, wenn berücksichtigt wird, was nach dem ersten erfolgreichen Demo passiert.
• Netzwerkpuffer und TLS-Overhead (einschließlich des schlimmsten Falls Verhaltens des Handshakes).
• Logging, Metriken und Absturz-Dumps, die Ingenieure später verlangen werden.
• OTA-Staging-Bereich sowie Metadaten für Integritätsprüfungen.
• Funktionserweiterung, die vorhersehbar nach dem Pilot-Feedback eintrifft.
Unzureichender Speicher bleibt oft zunächst unauffällig und wird später schmerzhaft, gerade dann, wenn Diagnosen und Aktualisierungssicherheit die hauptsächlichen Werkzeuge zur Kontrolle des Risikos im Feld werden.
Geräte, die als vertrauenswürdig angesehen werden, profitieren normalerweise von sicherem Boot, geschütztem Schlüsselspeicher, hardwareseitiger Krypto-Beschleunigung und einem echten Zufallszahlengenerator. Aus Deployment-Erfahrungen heraus fühlen sich Sicherheitsretrofits oft unangenehm an, da sie mit den Einschränkungen der ausgelieferten Hardware und langfristigen Anmeldeinformationen kollidieren.
Die Auswahl eines MCU (oder das Hinzufügen eines sicheren Elements), das starke Identität und gemessenes Boot unterstützt, reduziert oft die Menge an cleverer Software, die benötigt wird, um schwache Vertrauenswurzeln auszugleichen.
Der Zugang zu SWD/JTAG und die praktische Testbarkeit entscheiden in der Regel darüber, ob die frühe Fertigung kontrolliert oder chaotisch ist.
• SWD/JTAG-Zugangsplanung und Sperrstrategie für die Produktion.
• Testpads und probefreundliches Layout für Hochvolumen-Fixuren.
• Stromschienen-Sinnpunkte und messbare Knoten für schnelle Triage.
Eine kleine Menge an Testinfrastruktur kann Teams Wochen unbequemen Ratens ersparen, wenn die erste große Charge Randfälle aufdeckt, die bei handgebauten Prototypen nie aufgetreten sind.
Kommunikationsmodule
Das Kommunikationsmodul prägt mehr als nur das Linkbudget: Es beeinflusst die Bereitstellung, das Aktualisierungsverhalten, die Support-Workflows und überraschend viele Ausfallmodi.
In batteriebetriebenen Geräten dominiert oft das Radioverhalten den Energieverbrauch, sodass die Entscheidungen zur Konnektivität tendenziell als Entscheidungen zur Batterielebensdauer getarnt werden.
Die Auswahl balanciert in der Regel Reichweite, Latenz, Durchsatz, Topologie und Leistungsbudget, wobei der operative Reibung ehrlich begegnet wird.
• BLE für Kurzstrecken, niedrigen Stromverbrauch und Smartphone-Commissioning.
• Wi‑Fi für höheren Durchsatz mit höherem Spitzenstrom und strengeren Anforderungen an die Stromintegrität.
• Thread/Zigbee für Mesh-Netzwerke und energieeffiziente Heim-/Industrieeinsätze.
• LoRaWAN für lange Reichweite, niedrige Datenraten und strenge Payload-Disziplin.
• LTE‑M/NB‑IoT für breite Abdeckung mit Carrier-Einschränkungen und komplexerer Bereitstellung.
Teams fühlen oft Erleichterung, sobald sie zugeben, dass die "Radio-Auswahl" untrennbar mit der Firmware-Wiederholstrategien, dem Umgang mit Spitzenstrom und der Geduld des Benutzers während der Einrichtung verbunden ist.
Ein starkes Modul kann dennoch enttäuschen, wenn die Antenne schlecht platziert, durch das Gehäuse abgestimmt oder Lärm aus dem Erdungsrückfluss ausgesetzt ist.
• Antennenschutz-Zonierung und kontrollierte Impedanz-Routing.
• Gehäuseeffekte und Benutzereingangs-Interaktionstests.
• Überprüfungen der abgestrahlten Emissionen und Suszeptibilitätsprüfungen.
Wenn die Linkreserve dünn ist, können Firmware-Wiederholungen das Symptom eine Zeit lang maskieren, aber die Batteriekosten sammeln sich auf eine Art und Weise, die die Betriebsteams lange bemerken, bevor Ingenieure es im Labor sehen.
Das Design der Konnektivität muss realen Workflows standhalten, statt idealen Demos.
• Bereitstellung, die teilweise Ausfälle und häufige Benutzerfehler toleriert.
• Zurückhaltung und Wiederholungslogik, die selbstverursachte Batterieleerläufe vermeidet.
• Roaming-Verhalten sowie SIM/eSIM-Lebenszyklusmanagement für Mobilgeräte.
• OTA mit Authentifizierung, Rollback und bandbreitenbewusstem Scheduling.
OTA funktioniert weniger wie ein glänzendes Feature und mehr wie ein langfristiger Wartungskanal; wenn es nachlässig behandelt wird, neigen die Geräte dazu, teuer zu unterstützen zu werden, selbst wenn das erste Rollout gut aussieht.
Energiemanagement
Das Leistungsdesign hält das Gerät am Leben, wiederholbar und langweilig, im besten Sinne des Wortes. Es umfasst Regler, Laden, Brennstoffmessung, Lastumschaltung und Schutzentscheidungen, die sowohl Spitzenstromereignisse als auch tiefschlafliche Erwartungen bewältigen müssen.
Buck/Boost/LDO-Auswahl profitiert von der Bewertung der Effizienz über den gesamten Lastbereich, nicht nur über einen einzelnen Betriebspunkt. Der Quieszenzstrom im Schlafmodus entscheidet oft, ob ein Produkt den Batterieerwartungen entspricht.
Radios können scharfe Stromspitzen erzeugen; Bulk-Kapazität, niederohmiges Routing und stabile Regelkreise entscheiden in der Regel, ob das System während Transmission-Ausbrüche aktiv bleibt. Viele mysteriöse Rücksetzer lassen sich eher auf transiente Einbrüche als auf die Firmware zurückverfolgen, was eine demütigende, aber nützliche Lektion während der Integration sein kann.
Die Batterielebensdauer wird häufig im Schlaf gewonnen, wo kleine Leckagen sich zu messbaren Verlusten summieren.
• Konfiguration des Tiefschlafmodus mit nur den tatsächlich genutzten Weckquellen.
• RTC oder niederleistungs-Timer für regelmäßige Wecksignale.
• GPIO- oder Sensorinterrupts für ereignisgesteuerte Wecksignale.
• Energieschaltung für Sensoren und Peripheriegeräte, die keine kontinuierliche Vorspannung benötigen.
Die Messung des Schlafstroms frühzeitig auf echter Hardware und die Behandlung unerwarteter Mikroschwingungen als Fehler verhindern in der Regel das langsame Kriechen, bei dem viele "fast ausgeschalteten" Blöcke stillschweigend die Laufzeit beeinträchtigen.
Die Wahl des Lade-IC hängt von der Chemie, den thermischen Grenzen, den regulatorischen Vorschriften und der erwarteten Umgebung ab. Die Auswahl des Brennstoffs sollte die Genauigkeitsanforderungen über Temperatur, Last und Alterung widerspiegeln. Für den Einsatz im Freien oder in unbeheizten Umgebungen wird das Verhalten bei niedrigen Temperaturen häufig zum Treiber für die wahrgenommene Qualität, sodass konservative Spannungsschwellen und ehrliche Kapazitätsberichterstattung plötzliche Abschaltbeschwerden reduzieren.
Überstrom, Überspannung, umgekehrte Polarität und ESD-Verhalten sollten in vielen Einsätzen als Routinebetriebsbedingungen behandelt werden. Industriebereiche erzeugen häufig Kabelentladungsevents und induktive Transienten, die wie "schlechtes Glück" aussehen können, es sei denn, das Design anticipiert sie. Geeignete Klemmen, Sicherungen, TVS-Dioden, Einschaltstromregelung und Isolationsentscheidungen entscheiden oft darüber, ob ein Gerät seinen ersten Monat mit intaktem Ruf übersteht.
Speicherkomponenten
Der Speicher hält Firmware, Konfiguration, Zertifikate und Protokolle. Die Auswahl zwischen NOR/NAND-Flash, EEPROM, FRAM, eMMC oder microSD wird in der Regel durch Haltbarkeit, Leistung, BOM-Kosten und wie schmerzhaft ein korruptes Schreiben betriebsintern wäre, bestimmt.
Echte Geräte sind Browouts, Watchdog-Reset und partielle Schreibvorgänge ausgesetzt.
• Prüfziffern oder CRCs für Konfiguration und Protokolle.
• Wear Leveling oder begrenzte Schreibfrequenz für flashbasierte Medien.
• Journaling oder nur-anfügen-Records für Daten, die nicht halb geschrieben werden können.
Ein häufiges Betriebs-Muster ist das Ringpuffer-Logging mit begrenzten Schreibraten, das den stillen Verbrauch von Haltbarkeit einschränkt und dennoch genügend Breadcrumbs hinterlässt, um Probleme im Feld zu debuggen.
A/B-Firmware-Slots sowie verifiziertes Booten und Rollback-Logik bieten ein praktisches Sicherheitsnetz während unterbrochener Updates. Ohne diese Sicherheitsvorkehrungen kann ein einziger Stromausfall während eines Updates Geräte im Feld stranden. Produkte, die reibungslos skalieren, behandeln die Wiederherstellbarkeit typischerweise auf demselben Niveau wie den Versand von Funktionen, da die Supportkosten tendenziell mit der Qualität der Wiederherstellungsgeschichte korrelieren.
Zertifikate und Schlüssel sollten mit Blick auf Manipulationssicherheit und Zugriffssteuerung gespeichert werden, nicht nur irgendwo nicht-flüchtig. Selbst bei sicherem Speicher reduzieren Pläne zur Schlüsselrotation, Widerruf und Incident-Response die langfristige Exposition, wenn ein Credential ausläuft oder eine Flotte teilweise kompromittiert ist.
Schnittstellenkomponenten
LEDs, Displays, Tasten, Mikrofone, Kameras und biometrische Sensoren gestalten die Benutzerfreundlichkeit, ziehen jedoch auch Strom, EMV-Risiken und Datenschutzüberlegungen an. Eine Benutzeroberfläche, die unter Druck konsistent erscheint, spiegelt oft diszipliniertes elektrisches Design mehr wider als die Politur der Benutzeroberfläche.
Tasten benötigen in der Regel Entprellung und ESD-Schutz, um sporadische Fehlmessungen zu vermeiden.
Mikrofone und Kameras benötigen in der Regel saubere Spannungsversorgungen und sorgfältige Erdung, um intermittierende Artefakte zu vermeiden, die Benutzer als "tückisch" interpretieren.
• Trennung sensibler analoger Wege von hochstromschaltenden und RF-Wegen.
• Rückwegplanung zur Begrenzung der Geräuschkopplung.
• Abschirmungs- und Filterwahl, die mit dem Gehäuse- und Kabelstrategie übereinstimmen.
Intermittierende UI-Fehler werden häufig durch Kopplung von Radios oder Motoren verursacht, und es kann überraschend befriedigend sein, diese durch Layout- und Erdungsdisziplin anstelle endloser Firmware-Workarounds zu beheben.
Geräte verhalten sich vorhersehbarer, wenn sie eine Offline-Geschichte haben, die nicht auf die Verfügbarkeit des Netzwerks angewiesen ist.
Klare lokale Rückmeldungen (eindeutige LED-Zustände und minimale, genaue Fehlersignalisierung) reduzieren tendenziell die Supportlast und vermeiden die Benutzerfrustration, die aus stillem Fehlerverhalten resultiert.
Aktuatoren
Aktuatoren wandeln Steuerabsicht in Bewegung, Wärme oder Kraft um und erfordern normalerweise zusätzliche Schnittstellenschaltung über einen direkten MCU-Pin hinaus. Da Aktuatoren mit der physischen Welt interagieren, sind Fehlerarten häufig sichtbar, kostspielig und emotional eskalierend für die Benutzer. Motoren, Solenoide, Ventile und Relais benötigen häufig MOSFET-Stufen, H-Brücken oder dedizierte Treiber-ICs, die für reale Ströme und Transienten ausgelegt sind.
• Flyback-Dioden oder Snubber für induktive Lasten.
• Strommessung für Stellerkennung und Überlastreaktion.
• Thermische Entwurfserwägungen für kontinuierliche oder hochfrequente Lasten.
Die Erfahrung im Feld zeigt häufig aktorbezogene Probleme als häufige Fehlerquelle, und konservative Abwertung sowie Fehlererkennung verbessern tendenziell das Verhalten der Flotte in einer Weise, die Supportteams schnell bemerken.
Ein Gerät sollte sicher bleiben, wenn die Firmware abstürzt, die Cloud nicht erreichbar ist oder Befehle verspätet eintreffen.
• Watchdogs und Reset-Strategien, die mit sicheren Ausgängen abgestimmt sind.
• Standard-sichere Ausgangszustände, definiert pro Aktuator und pro Modus.
• Mechanische Sicherheitspositionen, wo die Anwendung dies erfordert.
Die widerstandsfähigsten Designs behandeln den Verlust der Konnektivität als einen normalen Betriebsmodus und definieren genau, was der Aktuator während dieser Zeit tut, sodass das Verhalten auch dann vorhersehbar bleibt, wenn alles andere unvollkommen ist.
Systemebene-Integration
Hochwirksame Verbesserungen stammen oft aus Integrationspraktiken, die das gesamte System zwingen, frühzeitig die Wahrheit zu sagen.
• Validierung der Leistungsintegrität unter den ungünstigsten Bedingungen mit Funk- und Aktuatorbelastung.
• Geräuschkontrolle über analoge Sensorik, Schaltregler und Hochstromtreiber.
• Start-, Aktualisierungs- und Wiederherstellungsabläufe mit messbaren Zuständen und klarer Beobachtbarkeit.
• Umwelttests (Temperatur, Luftfeuchtigkeit, Vibration), die gewählt werden, um den tatsächlichen Einsatzbedingungen zu entsprechen.
Wenn diese Aktivitäten als alltägliche Ingenieurarbeit und nicht als Endstadium-Zeremonie behandelt werden, werden die Auswahl der Komponenten in der Regel weniger dramatisch, und das Verhalten des Geräts bleibt tendenziell von Prototypen bis zur Massenproduktion konstant.
Fazit
Erfolgreiche IoT-Systeme basieren auf einem vollständigen und zuverlässigen Datenkreis, der Sensorik, Signalaufbereitung, Verarbeitung, Kommunikation, Sicherheit und Energiemanagement umfasst. Jede Phase beeinflusst die Gesamtleistung, Lebensdauer der Batterie, Genauigkeit und Benutzererfahrung. Durch das Gleichgewicht zwischen Hardware, Firmware, Netzwerk- und Betriebsconstraints können IoT-Geräte zuverlässige Überwachung, Steuerung und Automatisierung in einer Vielzahl von Anwendungen bieten.
Häufig gestellte Fragen [FAQ]
1. Warum scheitern viele IoT-Projekte aufgrund der Messqualität statt aufgrund von Konnektivitätsproblemen?
Der Konnektivität wird während der Entwicklung oft die meiste Aufmerksamkeit geschenkt, weil Dashboards und Cloud-Integrationen sehr sichtbar sind. Ungenaue Messungen, die durch schlechte Sensorplatzierung, Vibration, Luftströmung, thermische Kopplung, Geräusch oder Installationsfehler verursacht werden, können jedoch das gesamte System untergraben. Wenn die ursprünglichen Daten unzuverlässig sind, können selbst die fortschrittlichsten Analysen, Cloud-Plattformen und Kommunikationsnetze keine vertrauenswürdigen Entscheidungen treffen. Langfristiger IoT-Erfolg beginnt normalerweise mit stabilen Messungen und nicht mit ausgeklügelten Konnektivitätsfunktionen.
2. Warum sollte die Sensor-Montage als Teil des Sensorsystems selbst betrachtet werden?
Sensoren messen physikalische Bedingungen durch ihre Interaktion mit der umgebenden Umgebung. Montagekraft, Gehäusedesign, Kabelverlegung, Luftstrom, Vibrationsübertragung und thermischer Kontakt können alle beeinflussen, was der Sensor wahrnimmt. Ein perfekt kalibrierter Sensor kann dennoch irreführende Messwerte liefern, wenn er schlecht montiert ist. In vielen Einsätzen tragen installationsbedingte Fehler mehr zur Messunsicherheit bei als die Spezifikationen des Sensors selbst, was die mechanische Integration zu einem kritischen Bestandteil der allgemeinen Sensorleistung macht.
3. Warum ist Oversampling oft eine versteckte Bedrohung für die Batterielebensdauer in IoT-Geräten?
Die Daten häufiger als nötig abzutasten, erhöht die Verarbeitungsbelastung, den Speicherbedarf und die Kommunikationsaktivität. Da die drahtlose Übertragung häufig den größten Energieverbrauch in batteriebetriebenen IoT-Produkten darstellt, kann das Sammeln übermäßiger Daten indirekt die Funknutzung erhöhen und die Laufzeit verkürzen. Obwohl hohe Abtastraten die Genauigkeit zu verbessern scheinen, erzeugen sie oft größere Datensätze, ohne dass bedeutende Verbesserungen in der Entscheidungsqualität erzielt werden. Effektive Abtaststrategien balancieren die Anforderungen an die Ereigniserkennung gegen den Energieverbrauch und die Berichtserfordernisse aus.
4. Warum trennen erfolgreiche IoT-Geräte die Messlogik von der Entscheidungslogik?
Rohsensorwerte schwanken natürlich aufgrund von Rauschen, Umweltschwankungen und normalem Prozessverhalten. Wenn jede Messung direkt eine Aktion auslöst, können Systeme instabil werden und Fehlalarme erzeugen. Durch die Trennung der Messsammlung von der Entscheidungslogik mittels Hysterese, Zustandsmaschinen, Filterung, Zeitfenstern und Validierungsregeln können Geräte reaktionsfähig bleiben und unnötige Reaktionen auf vorübergehende Schwankungen vermeiden. Dieser Ansatz verbessert die Zuverlässigkeit und schafft ein vorhersehbareres Systemverhalten unter realen Bedingungen.
5. Warum werden viele kritische IoT-Entscheidungen lokal verarbeitet, anstatt sie an die Cloud zu delegieren?
Cloud-Systeme bieten wertvolle langfristige Analysen, Flottenmanagement und prädiktive Einblicke, jedoch können Netzwerkverzögerungen und -ausfälle sie für zeitkritische Schutzfunktionen ungeeignet machen. Ereignisse wie Überstrombedingungen, Überhitzung, Motorstillstände oder Sicherheitsabschaltungen erfordern oft sofortige Maßnahmen. Das Warten auf eine Bestätigung aus der Cloud könnte dazu führen, dass Geräteschäden oder unsichere Bedingungen entstehen. Aus diesem Grund werden kritische Schutz- und Steuerungsentscheidungen häufig am Edge ausgeführt, während Cloud-Plattformen sich auf Überwachung und Optimierung konzentrieren.
Verwandter Blog
-
Wie viele Nullen in einer Million, Milliarden, Billionen?
![Wie viele Nullen in einer Million, Milliarden, Billionen?]()
2024/07/29
Millionen repräsentieren 106, eine leicht griffbare Figur im Vergleich zu alltäglichen Gegenständen oder jährlichen Gehältern. Milliarden, entspr... -
IRLZ44N MOSFET -Datenblatt, Schaltung, Äquivalent, Pinout
![IRLZ44N MOSFET -Datenblatt, Schaltung, Äquivalent, Pinout]()
2024/08/28
Der IRLZ44N ist ein weit verbreiteter N-Kanal-Power-MOSFET.Es ist bekannt für seine hervorragenden Schaltkapazitäten und eignet sich sehr für zahlr... -
Batteriestemperatur zu niedrig, das Laden gestoppt.Wie repariere ich es?
![Batteriestemperatur zu niedrig, das Laden gestoppt.Wie repariere ich es?]()
2024/10/6
Das Ladeproblemen von Mobiltelefonen sind häufig, können jedoch effektiv verwaltet werden.Die Temperatur spielt eine große Rolle bei der Batterieff... -
BC547 Transistor umfassender Leitfaden
![BC547 Transistor umfassender Leitfaden]()
2024/07/4
Der BC547 -Transistor wird üblicherweise in einer Vielzahl elektronischer Anwendungen verwendet, die von grundlegenden Signalverstärkern bis hin zu ... -
Umfassende Anleitung zum SCR (Siliziumgesteuerte Gleichrichter)
![Umfassende Anleitung zum SCR (Siliziumgesteuerte Gleichrichter)]()
2024/04/22
Siliziumkontrollierte Gleichrichter (SCR) oder Thyristoren spielen aufgrund ihrer Leistung und Zuverlässigkeit eine entscheidende Rolle in der Energi... -
LR621, SR621SW, 364, AG1 -Batterieäquivalente und Ersatz
![LR621, SR621SW, 364, AG1 -Batterieäquivalente und Ersatz]()
2024/07/15
Die Batterien von LR621- und SR621SW -Tasten sind in kompakten elektronischen Geräten wie Uhren, kleinen Spielzeugen, Taschenrechnern und Fernschlüs... -
Ein vollständiger Leitfaden für Multiplexer und ihre Rolle in digitalen Systemen
![Ein vollständiger Leitfaden für Multiplexer und ihre Rolle in digitalen Systemen]()
2025/09/20
Multiplexer sind Komponenten in digitalen Systemen, mit denen mehrere Eingangssignale unter Verwendung binärer Logik- und Kontrollsignale in eine ein... -
Grundlagen von Op-Ampere-Schaltungen
![Grundlagen von Op-Ampere-Schaltungen]()
2023/12/28
In der komplizierten Welt der Elektronik führt uns eine Reise in ihre Geheimnisse ausnahmslos zu einem Kaleidoskop aus exquisiten und komplexen Schal... -
Vergleich der Unterschiede und Anwendungen von NMOs und PMOS
![Vergleich der Unterschiede und Anwendungen von NMOs und PMOS]()
2024/11/15
Das Verständnis der Unterschiede zwischen NMOS- und PMOS -Transistoren ist wichtig für die Gestaltung effizienter Schaltkreise.NMOs (N-Type-Metallox... -
CR2450 gegen CR2032 Vergleich: Alles was Sie wissen müssen
![CR2450 gegen CR2032 Vergleich: Alles was Sie wissen müssen]()
2025/09/15
Button -Batterien wie CR2450 und CR2032 führen viele alltägliche Elektronik aus, von Uhren und Fernbedienungen bis hin zu medizinischen und industri...









Heiße Teile
- CC0805JRNPO9BN471
- M68Z512W-70NC1
- 06033C101KAT4A
- TSUMU18TR-LF-1
- 0402ZC151JAT2A
- STM32L151VDT6
- IRF520A
- SH67P54F-DA018
- MTC20144TQ-I
- ISO722MD
- HA12169FB
- SGL160N60UFDTU
- STI71090WC
- XC2C128-6CPG132C
- FFAF60U60DNTU
- LLA319R71C474MA01L
- SMCJ250CA
- APM4410KC-TRL
- KB910LQA1
- MC143120B1DW
- ATTINY40-XU
- AU6366-D41-GDL-GR
- GS1572-IBE3
- K4B2G1646C-HCF8
- 1812CC222MAT1A
- T350H686K010AT
- F931E336MNC
- GQM1555C2D6R5CB01D
- TPS55340MRTETEP
- OPA333AQDBVRQ1
- AT91SAM9G35-CU
- 1808CC223KATBE
- RTD2270S-GR
- TAP105M020GSB
- AS3-15-24
- ADUM6020-5BRIZ
- STM32L151CBT6ATR
- T491C155K035ZTAC00
- ADL5902ACPZ
- BH28MA3WHFV
- HD6433038ME7FV
- ISP1016E-80LT44
- UPD78054GC-B08-8BT
- LM6044IM
- MTFC16GAKAECN-AI
- UL634H256SC-35Z
- MT3353CBDG
- R8A00013FP
- A3942KLGTR-T IC
- HI3751ARBCV8000D00